
Liquid AI, an MIT spinoff, launched its Liquid Foundation Models (LFM) in three sizes without using the current transformer architecture used by large language models (LLMs) with good performance.
According to Liquid, LFMs have "state-of-the-art performance at every scale" and have a smaller memory footprint and more efficient inference than LLMs. That efficiency could mean that LFMs will use less power and be more sustainable. After all, electricity is one of the biggest limiting factor for AI workloads and one big reason for the renaissance of nuclear power.
- Constellation Energy, Microsoft ink nuclear power pact for AI data center
- Generative AI driving interest in nuclear power for data centers
- DigitalOcean highlights the rise of boutique AI cloud providers
- Equinix, Digital Realty: AI workloads to pick up cloud baton amid data center boom
- The generative AI buildout, overcapacity and what history tells us
- AI infrastructure is the new innovation hotbed with smartphone-like release cadence
Simply put, we need more efficient models than taxing the grid, using too much water and throwing more GPUs at the issue. "Liquid AI shows that leading models don't have to come from deep pocketed large players and can also come from startups. The intellectual race for AI is far from being over," said Constellation Research analyst Holger Mueller.
LFMs are general-purpose AI models for any sequential data, including video, audio, text, time series and signals. Liquid will hold a launch event October 23 at MIT Kresge in Cambridge to talk about LFMs and applications in consumer electronics and other industries.
LFMs come in three sizes--1.3B, 3.1B and 40.3B mixture of experts (MoE)--and are available on Liquid Playground, Lambda, Perplexity Labs and Cerebras Inference. Liquid AI said its stack is being optimized for Nvidia, AMD, Qualcomm, Cerebras and Apple hardware.
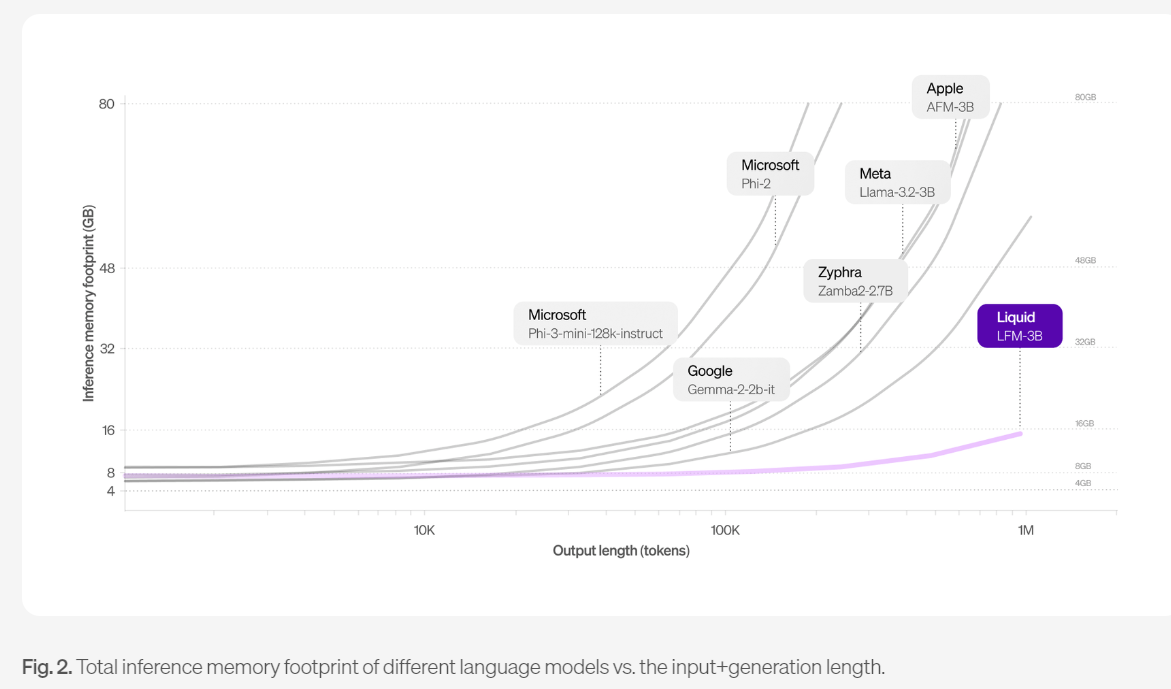
The smallest model from Liquid AI is built for resource-constrained environments with the 3.1B model focused on edge deployments.
Although it is early Liquid AI plans to "build private, edge, and on-premise AI solutions for enterprises of any size." The company added that it will target industries including financial services, biotech and consumer electronics.
Liquid AI has a bevy of benchmarks comparing its LFMs to LLMs and the company noted that the models are a work in progress. LFMs are good at general and expert knowledge, math and logical reasoning, long-context tasks and English. LFMs aren't good at zero-shot code tasks, precise numerical calculations, time-sensitive information and human preference optimization.
13 artificial intelligence takeaways from Constellation Research’s AI Forum
A few key points about LFMs and potential efficiency gains.
- Transformer models' memory usage surges for long inputs so they do not do edge deployments well. LFMs can handle long inputs without affecting generation speed or the amount of memory required.
- Training LFMs require less compute compared to GPT foundation models.
- The lower memory footprint means lower costs at inference time.
- LFMs can be optimized for platforms.
- LFMs could become more of an option as enterprises start to hot swap models based on use case. If LFMs do become an option more efficiency and lower costs would favor their increased adoption.
Bottom line: Liquid AI's LFMs may steer the conversation more toward efficiency over brute strength when it comes to generative AI. Should genAI become more efficient it could upend the current economic pecking order where all the spoils go to infrastructure players--Nvidia, Micron Technology, Broadcom and others.

