
Spark Summit East highlights progress on machine learning, deep learning and continuous applications combining batch and streaming workloads.
Despite challenges including a new location and a nasty Nor’easter that put a crimp on travel, Spark Summit East managed to draw more than 1,500 attendees to its February 7-9 run at the John B. Hynes Convention Center in Boston. It was the latest testament to growing adoption of Apache Spark, and the event underscored promising developments in areas including machine learning, deep learning and streaming applications.
The Summit had outgrown last year’s east coast home at the New York Hilton, but the contrast between those cramped quarters and the cavernous Hynes made comparison difficult. As I wrote of last year’s event, the audience was technical, and if anything, this year’s agenda seemed more how-to than visionary. There were fewer keynotes from big enterprise adopters and more from vendors.

Mataei Zaharia of Databricks recapped Spark progress last year, highlighting growing adoption
and performance improvements in areas including streaming data analysis.
The Summit saw plenty of mainstream talks on SQL and machine learning best practices as well as more niche topics, such “Spark for Scalable Metagenomics Analysis” and “Analysis Andromeda Galaxy Data Using Spark.” Standout big-picture keynotes included the following:
Mataei Zaharia, the founder of Spark and chief technology officer at Databricks, gave an overview of recent progress and coming developments in the open source project. The centerpiece of Zaharia’s talk concerned maturing support for continuous applications requiring simultaneous analysis of both historical and streaming, real-time information. One of the many use cases is fraud analysis, where you need to continuously compare the latest, streaming information with historical patterns in order to detect abnormal activity and reject possibly fraudulent transactions in real time.
Spark already addressed fast batch analytics, but support for streaming was previously limited to micro-batch (meaning up to seconds of latency) until last February’s Spark 2.0 release. Zaharia said even more progress was made with December’s Spark 2.1 release with advances on Structured Streaming, a new, high-level API that addresses both batch and stream querying. Viacom, an early beta customer, is using Structured Streaming to analyze viewership of cable channels including MTV and Comedy Central in real time while iPass is using it to continuously monitor WiFi network performance and security.
Alexis Roos, a senior engineering manager at Salesforce, detailed the role of Spark in powering the machine learning, natural language processing and deep learning behind emerging Salesforce Einstein capabilities. Addressing the future of artificial intelligence on Spark, Ziya Ma, a VP of Big Data Technologies at Intel, offered a keynote on “Accelerating Machine Learning and Deep Learning at Scale with Apache Spark.” James Kobielus of IBM does a good job of recapping Deep Learning progress on Spark in this blog.
Ion Stoica, executive chairman of Databricks, picked up where Zaharia left off on streaming, detailing the efforts of UC Berkeley’s RISELab, the successor of AMPLab, to advance real-time analytics. Stoica shared benchmark performance data showing advances promised by Apache Drizzle, a new streaming execution engine for Spark, in comparison with Spark without Drizzle and streaming-oriented rival Apache Flink.
Stoica stressed the time- and cost-saving advantages of using a single API, the same execution engine and the same query optimizations to address both streaming and batch workloads. In a conversation after his keynote, Stoica told me Drizzle will likely debut in Databricks’ cloud-based Spark environment within a matter of weeks and he predicted that it will show up in Apache Spark software as soon as the third quarter of this year.
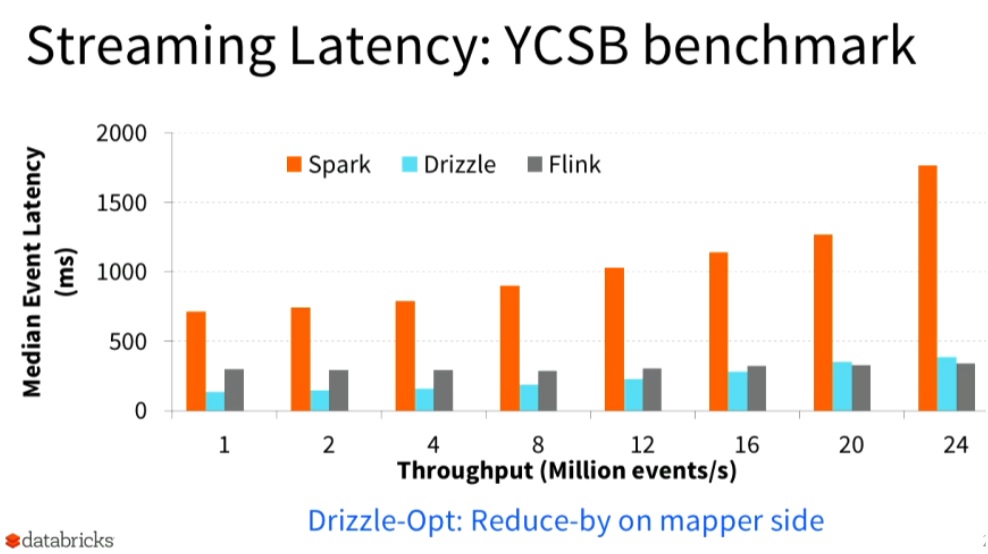
The Apache Drizzle execution engine being developed by RISELabs promises better
streaming query performance as compared to today’s Spark or Apache Flink.
MyPOV of Spark Progress
Databricks is still measuring Spark success in terms of number of contributors and number of Spark Meetup participants (the latter count is 300,000-plus, according to Zaharia), but to my mind, it’s time to start measuring success by mainstream enterprise adoption. That’s why I was a bit disappointed that the Summit’s list of presenters in the CapitalOne, Comcast, Verizon and Walmart Labs mold was far shorter than the list of vendors and Internet giants like Facebook and Netflix presenting.
Databricks says it now has somewhere north of 500 organizations using its hosted Spark Service, but I suspect the bulk of mainstream Spark adoption is now being driven by the likes of Amazon (first and foremost) as well as IBM, Google, Microsoft and others now offering cloud-based Spark services. A key appeal of these sources of Spark is the availability of infrastructure and developer services as well as broader analytical capabilities beyond Spark. Meanwhile, as recently as last summer I heard Cloudera executives assert that the company’s software distribution was behind more Spark adoption than that of any other vendor.
In a though-provoking keynote on “Virtualizing Analytics,” Arsalan Tavakoli, Databricks’ VP of customer engagement, dismissed Hadoop-based data lakes as a “second-generation” solution challenged by disparate and complex tools and access limited to big data developer types. But Tavakoli also acknowledged that Spark is only “part of the answer” to delivering a “new paradigm” that decouples compute and storage, provides uniform data management and security, unifies analytics and supports broad collaboration among many users.
Indeed, it was telling when Zaharia noted that 95% of Spark users employ SQL in addition to whatever else they’re doing with the project. That tells me that Spark SQL is important, but it also tells me that as appealing as Spark’s broad analytical capabilities and in-memory performance may be, it’s still just part of the total analytics picture. Developers, data scientists and data engineers that use Spark are also using non-Spark options ranging from the prosaic, like databases and database services and Hive, to the cutting edge, such as emerging GPU- and high-performance-computing-based options.
As influential, widely adopted, widely supported and widely available as Spark may now be, organizations have a wide range of cost, latency, ease-of-development, ease-of-use and technology maturity considerations that don’t always point to Spark. At least one presentation at Spark Summit cautioned attendees not to think of Spark Streaming, for example, as a panacea for next-generation continuous applications.
Spark is today where Hadoop was in 2010, as measured by age, but I would argue that it’s progressing more quickly and promises wider hands-on use by developers and data scientists than that earlier disruptive platform.
Related Reading:
Spark Summit East Report: Enterprise Appeal Grows
Spark On Fire: Why All The Hype?

