
Nvidia launched Blackwell Ultra, which aims to boost training and test time inference, as the GPU giant makes the case that more efficient models such as DeepSeek still require its integrated AI factory stack of hardware and software.
The company also launched Dynamo, an open-source framework that disaggregates the AI reasoning process to optimize compute. For good measure, Nvidia laid out its plans for the next two years.
In the leadup to Nvidia GTC, where Blackwell Ultra was announced by CEO Jensen Huang, has been interesting. The rise of DeepSeek and models that can efficiently reason at lower costs created some doubt about whether hyperscalers would need to spend heavily on Nvidia's stack.
- DeepSeek: What CxOs and enterprises need to know
- DeepSeek's real legacy: Shifting the AI conversation to returns, value, edge
- Nvidia strong Q4, outlook eases AI infrastructure spending fears for now
Huang said that Blackwell Ultra boosts training and test-time scaling inference. The idea is that applying more compute during inference improves accuracy and paves the way for AI reasoning, agentic AI and physical AI. "Reasoning and agentic AI demand orders of magnitude more computing performance," said Huang, who noted that Blackwell Ultra is a versatile platform for pre-training, post-training and reasoning AI inference. "The amount of computation we need at this point as a result of agentic AI as a result of reasoning, is easily 100 times more than we thought we needed."

Nvidia's Huang in his keynote at Nvidia GTC made the case that Blackwell shipments are surging and that the insatiable demand for AI compute--and Nvidia's stack--continues. Huang said Nvidia's roadmap is focused on building out AI factories and laying out investments years in advance. "We don't want to surprise you in May," said Huang.
In a nutshell, Nvidia is sticking to its annual cadence, but sticking with the same chassis. The roadmap consists of the following:
Vera Rubin in second half of 2026.

Rubin Ultra in second half of 2027.

Huang said Nvidia's annual cadence is about "scaling up, then scaling out."
To that end, Huang noted that Nvidia's roadmap will require bets on networking and photonics.


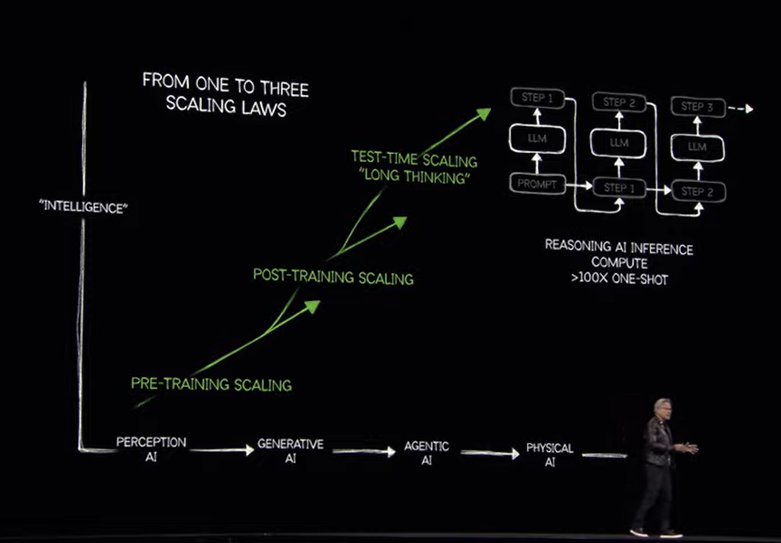
Key points about Blackwell Ultra include:
- The platform is built on the Blackwell architecture launched a year ago.
- Blackwell Ultra includes Nvidia GB300 NVL72 rack-scale system and the Nvidia HGX B300 NVL16 system.
- Nvidia GB300 NVL72 connects 72 Blackwell Ultra GPUs and 36 Arm
- Neoverse-based NVIDIA Grace CPUs. That setup enables AI models to tap into compute to come up with different solutions to problems and break down requests into steps.
- GB300 NVL72 has 1.5x the performance of its predecessor.
- Nvidia argued that Blackwell Ultra can increase the revenue opportunity of 50x for AI factories compared to Hopper.
- GB300 NVL72 will be available on DGX Cloud, Nvidia's managed AI platform.
- Nvidia DGX SuperPOD with DGX GB300 systems use the GB300 NVL72 rack design as a turnkey architecture.
Blackwell Ultra is aimed at agentic AI, which will need to reason and act autonomously, and physical AI, which is critical to robotics and autonomous vehicles.
To scale out Blackwell Ultra, Nvidia said the platform will integrate with its Nvidia Spectrum-X Ethernet and Nvidia Quantum-X800 InfiniBand networking systems. Cisco, Dell Technologies, HPE, Lenovo and Supermicro are vendors that will offer Blackwell Ultra servers in addition to a bevy of contract equipment providers. Cloud hyperscalers AWS, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure will offer Blackwell Ultra instances along with specialized GPU providers such as CoreWeave, Crusoe, Nebius and others.
Constellation Research analyst Holger Mueller said:
"Nvidia is doubling down on its platform with Blackwell Ultra but also the the software and storage stack. At the same time Nvidia knows it has to fight to stay in the cloud data center as the cloud vendors are building out their inhouse AI platforms. Robotic automation - creating workloads for Nvidia is another strategy thar Huang and team are pursuing.
Huang threw chipmaking in a tizzy announcing Blackwell in a 1 year cycle from Hopper, unheard of in chip making. Nvidia has delivered.
The question is how do Nvidia's plans stack up vis-a-vis the cloud vendors in-house plans. Do AWS and Microsoft have a chance? Does Nvidia cut into Google's TPU lead? If Nvidia can have AWS and Microsoft give up building their custom chips it's a mega win."
Dynamo: An open-source inference framework
Blackwell-powered systems will include Nvidia Dynamo, which is designed to scale up reasoning AI services. Nvidia Dynamo is designed to maximize token revenue generation and orchestrate and accelerate inference communication across GPUs. Huang said Dynamo is the "operating system of the AI factory."
Dynamo separates the processing and generation phases of large language models on different GPUs. Nvidia said Dynamo optimizes each phase to be independent and maximize resources.
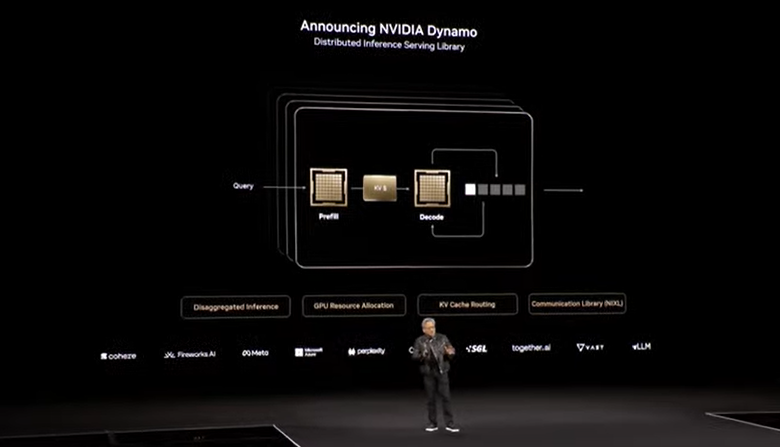
Key points about Dynamo include:
- Dynamo succeeds Nvidia Triton Inference Server.
- By disaggregating workloads, Dynamo can double the performance of AI factories. Dynamo features a GPU planning engine, an LLM-aware router to minimize repeating results, low-latency communication library and a memory manager.
- When running the DeepSeek-R1 model on a large cluster of GB200 NVL72 racks, Dynamo boosts the number of tokens by 30x per GPU.
- Dynamo is fully open source and supports PyTorch, SGLang, Nvidia TensorRT-LLM and vLLM.
- Dynamo maps the knowledge that inference systems hold in memory from serving prior requests (KV cache) across thousands of GPUs. It then routes new inference requests to GPUs that have the best match.

