Meta launched its next-generation training and inferencing processor as it optimizes models for its recommendation and ranking workloads.
The second version of the Meta Training and Inference Accelerator (MTIA) highlights how cloud hyperscale players are creating their own processors for large language model (LLM) training and inferencing.
Intel launched its Gaudi 3 accelerator on Tuesday to better compete with AMD and Nvidia. Google Cloud outlined new tensor processor units and Axion, an ARM-based custom chip. AWS has Trainium and Inferentia processors and Microsoft is building out its own AI chips. The upshot is rivals to Nvidia as well as huge customers such as Meta are looking to bring costs down. Why enterprises will want Nvidia competition soon
- Nvidia Huang lays out big picture: Blackwell GPU platform, NVLink Switch Chip, software, genAI, simulation, ecosystem
- Will generative AI make enterprise data centers cool again?
- AWS presses custom silicon edge with Graviton4, Trainium2 and Inferentia2
- Intel's AI everywhere strategy rides on AI PCs, edge, Xeon CPUs for model training, Gaudi3 in 2024
- AMD Q4 solid
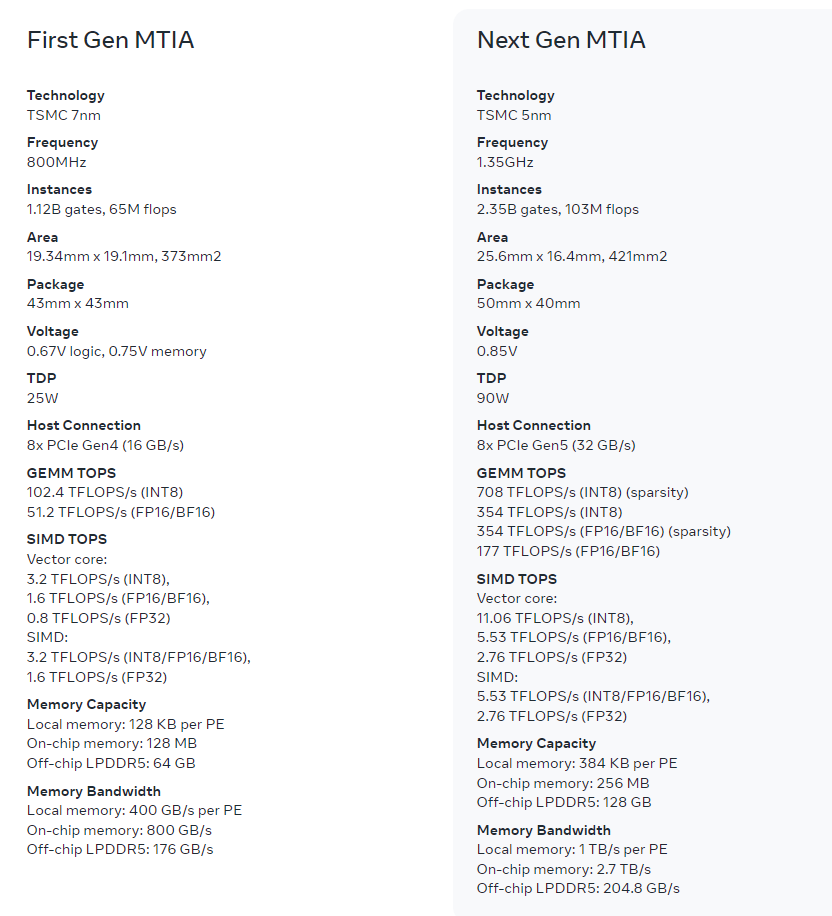
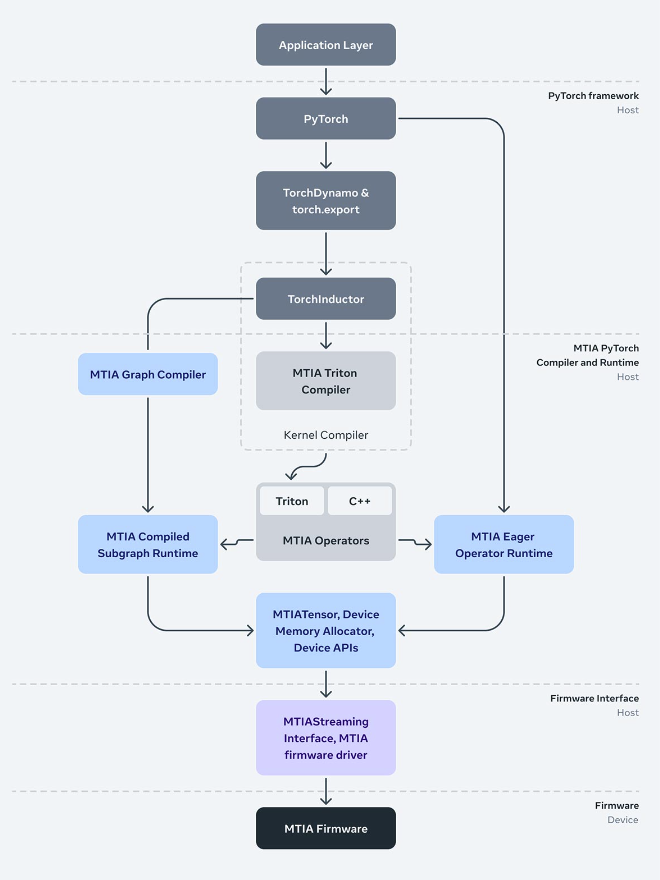
MTIA.v2 more than doubles compute and memory bandwidth compared to its predecessor released last year. MTIA is only one part of Meta's plan to build its own infrastructure. Meta also updated its PyTorch software stack to account for the updated MTIA processors.
In a blog post, Meta noted:
"MTIA has been deployed in our data centers and is now serving models in production. We are already seeing the positive results of this program as it’s allowing us to dedicate and invest in more compute power for our more intensive AI workloads.
The results so far show that this MTIA chip can handle both low complexity and high complexity ranking and recommendation models which are key components of Meta’s products. Because we control the whole stack, we can achieve greater efficiency compared to commercially available GPUs (graphics processing units)."
Like other cloud providers such as Google Cloud and AWS, Meta will still purchase Nvidia GPUs and accelerators in bulk, but custom silicon efforts highlight how AI model training and inference workloads will aim to balance cost, speed and efficiency. Not every model needs to be trained by the best processors available.
Here's a look at the MTIA processor comparisons followed by the software stack Meta has deployed.