
Cloudera has restructured amid intensifying cloud competition. Here’s what customers can expect.
Cloudera’s plan is to lead in machine learning, to disrupt in analytics and to capitalize on customer plans to move into the cloud.
It’s a solid plan, for reasons I’ll explain, but that didn’t prevent investors from punishing the company on April 3 when it offered a weaker-than-expected guidance for its next quarter. Despite reporting 50-percent growth for the fiscal year ended January 31, 2018, Cloudera’s stock price subsequently plunged 40 percent.
Cloudera’s narrative, shared at its April 9-10 analyst and influencers conference, is that it has restructured to elevate customer conversations from tech talk with the CIO to a C-suite and line-of-business sell about digital transformation. That shift, they say, could bring slower growth (albeit still double-digit) in the short term, but executives say it’s a critical transition for the long term. Investors seem spooked by the prospect of intensifying cloud competition, but here’s why Cloudera expects to keep and win enterprise-grade customers.
It Starts With the Platform
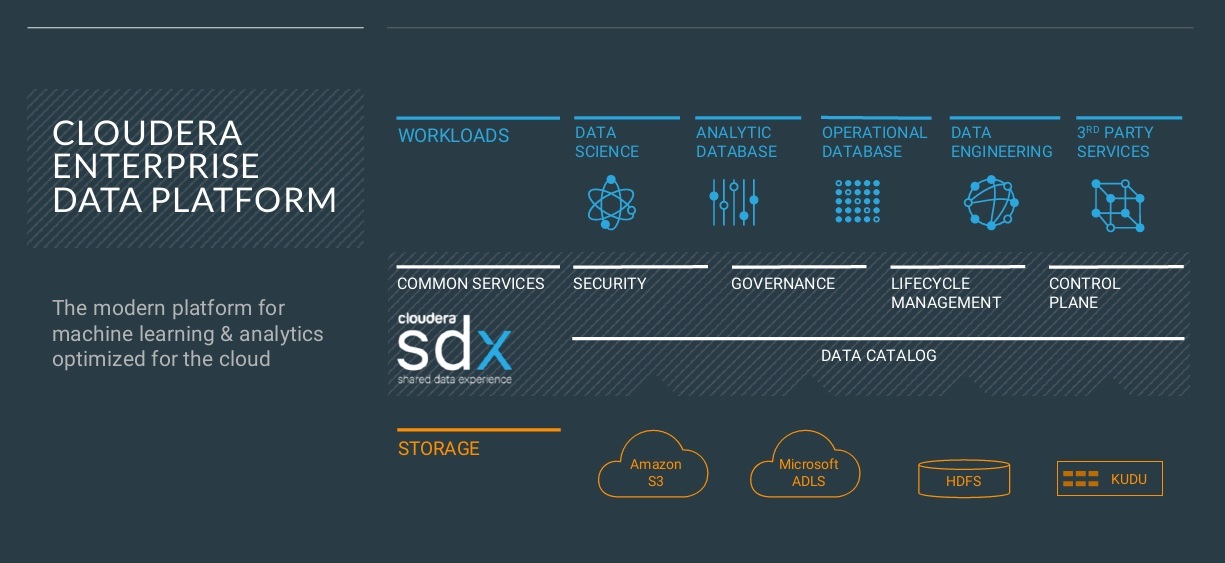
Cloudera defines itself as an enterprise platform company, and it knows enterprise customers want hybrid and multi-cloud options. Cloudera’s options now range from on-premises on bare metal to private cloud to public cloud on infrastructure as a service to, most recently, Cloudera Altus public cloud services, available on Amazon Web Services (AWS) and Microsoft Azure.
Supporting all these deployment modes is, of course, something that AWS and Google Cloud Platform (GCP) don’t do and that Microsoft, IBM, and Oracle do exclusively in their own clouds. The key differentiator that Cloudera is counting on is its Shared Data Experience. SDX gives customers the ability to define and share data access and security, data governance, data lifecycle management and deployment management and performance controls across any and all deployment modes. It’s the key to efficiently supporting both hybrid and multi-cloud deployments. Underpinning SDX is a shared data/metadata catalog that spans deployment modes and both cloud- and on-premises storage options, whether they are Cloudera HDFS or Kudu clusters or AWS S3 or Azure Data Lake object stores.
As compelling as public cloud services such as AWS Elastic MapReduce may sound, from the standpoint of simplicity, elasticity and cost, Cloudera says enterprise customers are sophisticated enough to know that harnessing their data is never as simple as using a single cloud service. In fact, the variety of services, storage and compute variations that have to be spun up, connected and orchestrated can get quite extensive. And when all those per-hour meters are running the collection of services can also get surprisingly expensive. When workloads are sizeable, steady and predictable, many enterprises have learned that it can be much more cost effective to handle it on-premises. If they like cloud flexibility, perhaps they’ll opt for a virtualized private-cloud approach rather than going back to bare metal.
With more sophisticated and cost-savvy customers in mind, Cloudera trusts that SDX will appeal on at least four counts:
- Define once, deploy many: IT can define data access and security, data governance, data lifecycle, and performance management and service-level regimes and policies once and apply them across deployment models. All workloads share the same data under management, without having to move data or create copies and silos for separate use cases.
- Abstract and simplify: Users get self-service access to resources without having to know anything about the underlying complexities of data access, deployment, lifecycle management and so on. Policies and controls enforce who sees what, which workloads run where and how resources are managed and assigned to balance freedom and service-level guarantees.
- Provide elasticity with choice: With its range of deployment options, SDX gives enterprises more choice and flexibility than a cloud-only provider in terms of how it meets security, performance, governance, scalability and cost requirements.
- Avoid lock-in: Even if the direction is solidly public cloud, SDX gives enterprises options to move workloads between public clouds and to negotiate better deals knowing they won’t have to rebuild their applications if and when they switch providers.
MyPOV on SDX
The Shared Data Experience is compelling, though at present it’s three parts reality and one part vision. The shared catalog is Hive and Hadoop centric, so Cloudera is exploring ways to extend the scope of the catalog and the data hub. Altus services are generally available for data engineering, but only recently entered beta (on AWS) for analytics deployments and persisting and managing SDX in the cloud. General availability of Cloudera Analytics and SDX services on Azure is expected later this year. Altus Data Science is on the roadmap, as are productized ways to deploy Altus services in private clouds. For now, private cloud deployments are entirely on customers to manage. In short, the all-options-covered rhetoric is a bit ahead of reality, but the direction is clear.
Machine Learning, Analytics and Cloud
Cloudera is counting on these three growth areas, so much so that it last year appointed general managers of each domain and reorganized with dedicated product development, product management, sales and profit-and-loss responsibility. At Cloudera's analyst and influencers conference, attendees heard presentations by each of the new GMs: Fast Forward Labs founder Hilary Mason on ML, Xplain.io co-founder Anupam Singh on analytics, and Oracle and VMware veteran Vikram Makhija on Cloud.
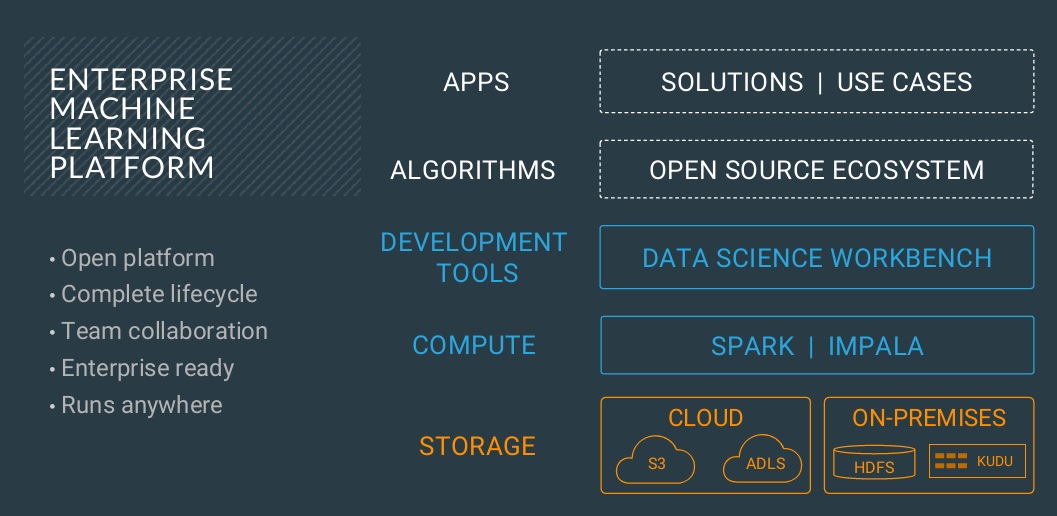
Lead in Machine Learning. The machine learning strategy is to help customers develop and own their ability to harness ML, deep learning and advanced analytical methods. They are “teaching customers how to fish” using all of their data, algorithms of their choice and running workloads in the deployment mode of their choice. (This is exactly the kind of support executives wanted at a global bank based in Denmark, as you can read in my recent “Danske Bank Fights Fraud with Machine Learning and AI” case study report.)
Cloudera last year acquired Mason’s research and consulting firm Fast Forward Labs with an eye toward helping customers to overcome uncertainty on where and how to apply ML methods. The Fast Forward team offers applied research (meaning practical, rather than academic), strategic advice and feasibility studies designed to help enterprises figure out whether they’re pursuing the right problems, setting realistic goals, and gathering the right data.
On the technology side, Cloudera’s ML strategy rests on the combination of SDX and the Cloudera Data Science Workbench (CDSW). SDX addresses the IT concerns from a deployment, security and governance perspective while CDSW helps data scientists access data and manage workloads in self-service fashion, coding in R, Python or Scala and using analytical, ML and DL libraries of their choice.
MyPOV on Cloudera ML. Here, too, it’s a solid vision with pieces and parts that have yet to be delivered. As mentioned earlier, Altus Data Science is on the roadmap (not even in beta), as are private-cloud and Kubernetes support. Also on the roadmap are model-management and automation capabilities that enterprises need at every stage of the model development and deployment lifecycle as they scale up their modeling work. Here’s where Azure Machine Learning and AWS SageMaker, to name two, are steps ahead of the game.
I do like that Cloudera opens the door to any framework and draws the line at data scientist coding with DSW, leaving visual, analyst-level data science work to best-of-breed partners such as Dataiku, DataRobot, H2O and RapidMiner.
Disrupt in Analytics. It was eye opening to learn that Cloudera gets the lion’s share of its revenue from analytics -- more than $100 million out of the company’s fiscal year 2018 total of $367 million in revenue. One might think of Cloudera as being mostly about big, unstructured data. In fact it’s heavily about disrupting the data warehousing status quo and enabling new, SQL-centric applications with the combination of the Impala query engine, the Kudu table store (for streaming and low-latency applications), and Hive on Apache Spark.
Cloudera analytics execs say they’re having a field day optimizing data warehouses and consolidating dedicated data marts (on Netezza and other aging platforms) now seen are expensive silos, requiring redundant infrastructure and copies of data. With management, security, governance and access controls and policies established once in SDX, Cloudera says IT can support myriad analytical applications without moving or copy data. That data might span AWS S3 buckets, Azure Data Lakes, HDFS, Kudu or all of the above.
The new news in analytics is that Cloudera is pushing to give DBA types all the performance-tuning and cost-based analysis options they’re used to having in data warehousing environments. Cloudera already offered its Analytic Workbench (also known as HUE) for SQL query editing. What’s coming, by mid year, is a consolidated performance analysis and recommendation environment. Code named Workload 360 for now, this suite will provide end-to-end guidance on migrating, optimizing and scaling workloads. To be delivered as a cloud service, this project combines Navigator Optimizer (tools acquired with Xplain.io) with workload analytics capabilities introduced with Altus. Think of it as a brain for data warehousing that will help companies streamline migrations, meet SLAs, fix lagging queries and proactively avoid application failures.
MyPOV on Analytics. Workload management tools are a must for heavy duty data warehousing environments, so this analysis-for-performance push is a good thing. Given the recent push into autonomous database management, notably by Oracle, I would have liked to have heard more about plans for workload automation.
Cloudera also didn’t have much to say about the role of Hive and Spark for analytical and streaming workloads, but I suspect they are significant. I’ve also talked to Cloudera customers (read “Ultra Mobile Takes an Affordable Approach to Agile Analytics”) that tap excess relational database capacity to support low-latency querying rather than relying on Impala, Hive or a separate Kudu cluster. Hive, Spark and conventional database services or capacity fall into the category of practical, cost-conscious options that may not drive additional Cloudera analytics revenue, but it’s an open platform that gives customers plenty of options.
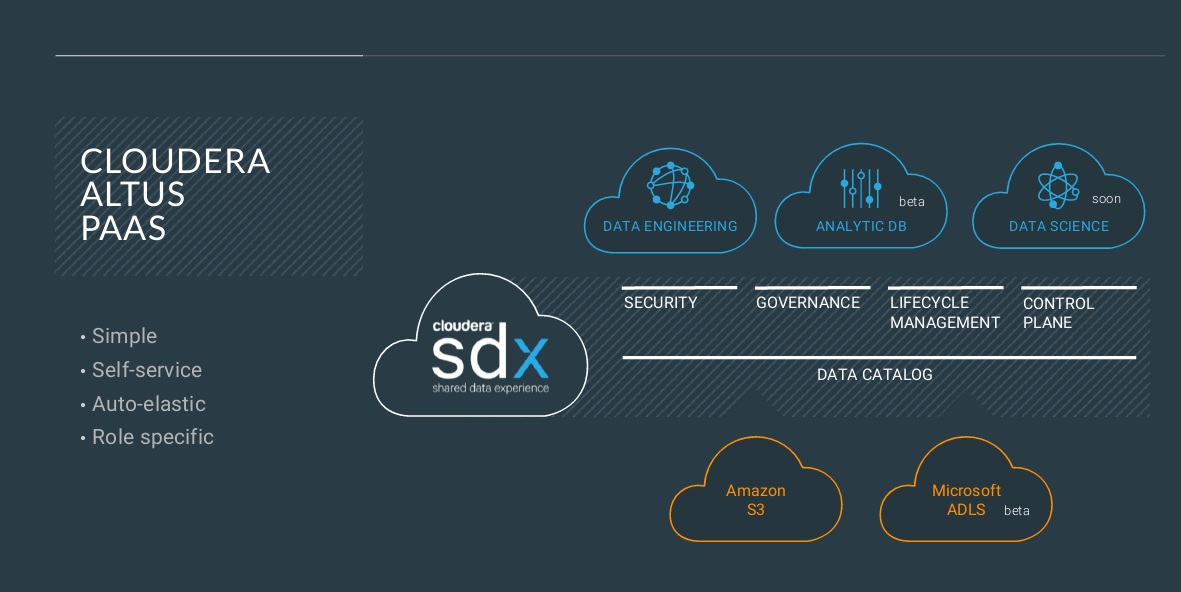
Capitalize on the Cloud. As noted above, SDX and the growing Altus portfolio are at the heart of Cloudera’s cloud plans. Enough said about the pieces still to come or missing. I see SDX as compelling, and it’s already helping customers to efficiently run myriad data engineering and analytic workloads in hybrid scenarios. But as a practical matter, many companies aren’t that sophisticated and are choosing to keep things simple with binary choices: X data and use case on-premises and Y data and use case in the cloud. Indeed, one of Cloudera’s customer panel guests acknowledged the importance of avoiding cloud lock in; nonetheless, he said his firm is considering the “simplicity” versus data/application portability tradeoffs of using Google Cloud Platform-native services.
MyPOV on Cloudera Cloud. Binary thinking is not the way to harness the power of using all your data, and it can lead to overlaps, redundancies and need of moving and copying data. Nonetheless, handling X on premises and Y in the cloud may be seen as the simpler and more obvious way to go, particularly if there are natural application, security or organizational boundaries. Cloudera has to execute on its cloud vision, develop a robust automation strategy and demonstrate to enterprises, with plenty of customer examples, that the SDX way is simpler and more cost-effective way to go and a better driver of innovation than binary thinking.
Related Reading:
Nvidia Accelerates AI, Analytics with an Ecosystem Approach
Danske Bank Fights Fraud With Machine Learning and AI
Ultra Mobile Takes an Affordable Approach to Agile Analytics

