
Amazon Web Services CEO Andy Jassy invoked the Lauren Hill song “Everything is Everything” at this week’s re:Invent event in Las Vegas to underscore his assertion that AWS has more than twice the number of services of any other public cloud. The question is, will the services catalog ever become – or, indeed, is it already – so extensive that it becomes unwieldy from a customer development, deployment, and cost-management perspective?
This year’s re:Invent followed the more-more-more pattern of past events, with more attendees, more exhibitors, more floor space and, you guessed it, yet more services and capabilities announced. That was certainly the case in the data and analytics arenas, with announcements across database, big-data management, analytics, machine learning (ML) and artificial intelligence (AI). Sometimes less is more, however, a point I’ll get back to in my conclusion, but let’s start with a recap of what I see as the most important data-to-decisions related announcements.
Aurora Upgrades Promise Easier Deployment, Cost Saving and Compatibility
Aurora is Amazon’s flagship database service, aimed at winning converts from the likes of Oracle Database, Microsoft SQL Server and IBM Db2 with what AWS says is comparable or better durability, availability and performance at as little as one tenth the cost. Aurora is a decidedly commercial offering, too (only available on AWS), but it’s compatible with both MySQL and, as of October, PostgreSQL, the two most popular open-source relational databases. Aurora launched with MySQL compatibility, but PostgreSQL offers closer compatibility with enterprise-focused capabilities supported in Oracle and Microsoft SQL Server.
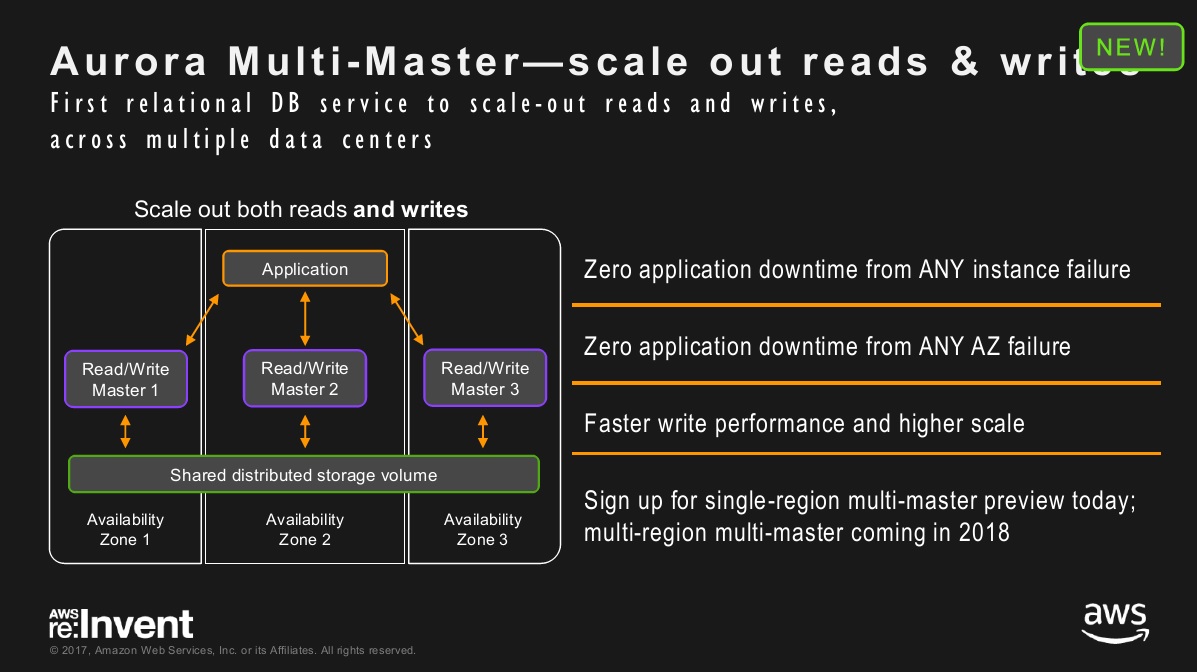
At Re:Invent, AWS announced two Aurora upgrades. Aurora Serverless (now in preview) will deliver automatic, on-demand scaling (both up and down), which will simplify deployment, ease ongoing management and align cost with usage. Aurora Multi-Master, another preview capability, scales both reads (already available) and writes (the part that’s new). Sometime next year this Multi-Master capability will be extendable across multiple regions. In short, Multi-Master promises performance, consistency and high-availability at scale, and with multi-region support these traits will span even global deployments.
MyPOV on Aurora upgrades: The Serverless move was a no-brainer and it was only a matter of time. Multi-Master may be a response to customer demand, as AWS claimed, but it also answers Google’s introduction of Spanner, that vendor’s globally scalable relational database. (Similarly, the DynamoDB Global Tables announcement at re:Invent answers Microsoft's introduction of global-capable CosmosDB). Global deployment is far from a mainstream demand, however, so this is more of a battle for bragging rights. The real mainstream market changer is the general availability PostgreSQL compatibility, which will make it easier to migrate workloads running on Oracle or SQL Server into AWS on Aurora without extensively rewriting queries and database functionality. It’s a less flashy announcement, but it’s the most significant in terms of winning new customers.
Neptune Graph Database Service

AWS entered a whole new database category with the introduction of Neptune, a graph database service now in “limited preview.” Graph analysis is about exploring network relationships, as in people in a social network; customers and influencers in a retail or telco environment; employees, candidates, organizations and job openings in an HR context; and network nodes and assets in a national-intelligence, security or IT-network analysis context.
Most companies use graph-analysis features that have been grafted onto relational databases to do this work. But graph databases designed for the task do a better, more flexible job when exploring millions or even billions of relationships. To give customers a choice, AWS has designed Neptune to use both the Property Graph and W3C's Resource Description Framework (RDF) models and their respective query languages, Apache TinkerPop Gremlin and RDF SPARQL.
MyPOV on Neptune: Amazon made some pretty sweeping disparaging statements about the scalability, durability and performance of existing open source and commercial graph database options. Neo4j, which is an open-source database with commercial enterprise edition and managed service options, supports both clustering and, more recently, multi-data-center deployment. Neptune is in limited preview, so we can only take Amazon’s word that it will deliver better and more reliable performance. Neptune will compete most directly with Neo4j and Titan/JanusGraph, from a technology perspective. But the real competition and biggest market opportunity is making a dent in the use of less-adept graph analysis features of more expensive databases including Oracle and Microsoft SQL Server. IBM has released Compose for JanusGraph, so it, too, is betting on a graph database service.
SageMaker Introduces Yet Another Model-Management Environment
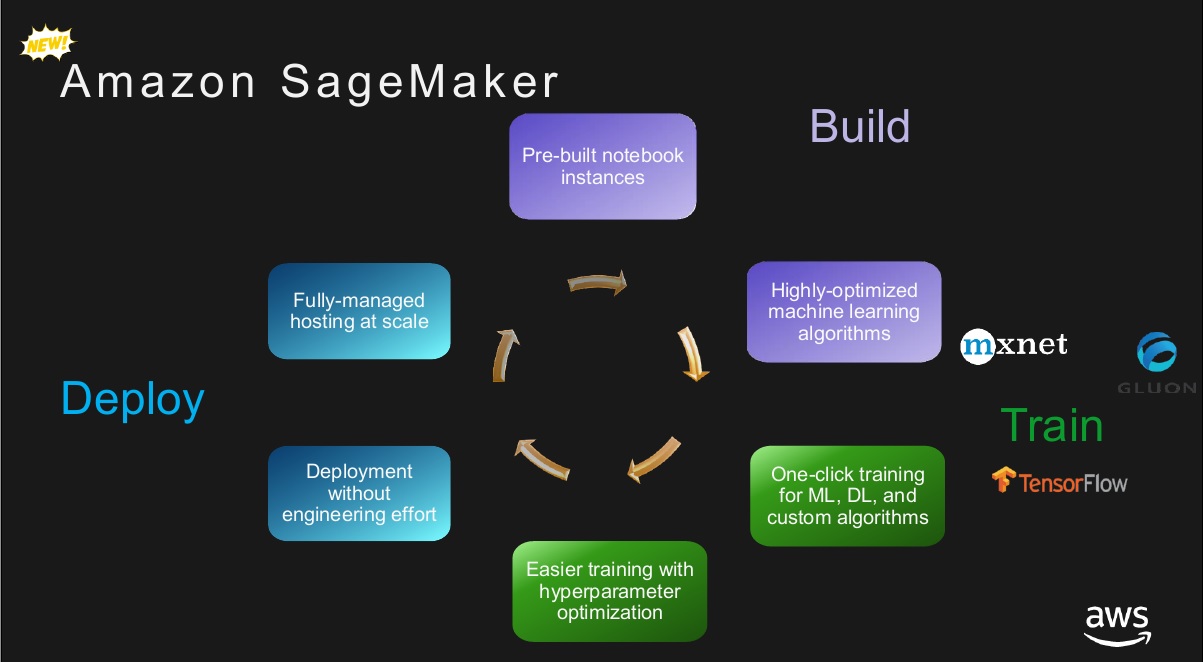
How many times this year have I heard vendors talking about making data science easier -- particularly ML? Let’s see, there’s Cloudera’s Data Science Workbench, IBM’s Data Science Experience, Microsoft’s next-generation Azure ML, Databricks (on AWS) and soon-to-be released on Azure… I’m sure there are more. At re:Invent AWS announced that Amazon SageMaker will join the crowd.
The idea with SageMaker (like the others) is to make it easier for data scientists, developers and data-savvy collaborators to build, train and run models at scale. A lot of these model-management environments rely on open-source notebooks, and that’s the case with SageMaker, too, as it uses Jupyter notebooks. Options for model building include a top drawer of 10 popular algorithms that AWS says have been optimized to run on its infrastructure, thereby improving performance and saving money on compute requirements. You can also use options from TensorFlow, MXNet and, soon, other frameworks, AWS promises, giving customers choice.
That’s a good start, but a key differentiator for SageMaker comes in lifecycle stages including training, where three’s a “one-click” option for serverless, autoscaling training. That’s one area where there’s typically a lot of manual work. Other time and labor savers include auto hyperparameter tuning (in preview) and one-click deployment, also with serverless autoscaling.
MyPOV on SageMaker: The training and deployment automation features sound very promising, but you’ll have to forgive me for taking a wait-and-see attitude after so many announcements this year. The other model-management environment I was impressed by this year was Microsoft’s next-generation Azure ML, which is currently in preview. Microsoft’s environment promises data-lineage and model-change auditing throughout the development and deployment lifecycle. SageMaker doesn’t offer these capabilities currently, but an executive told me AWS expects to add them.
Data-lineage, auditability and transparency are crucial not just for regulated banks and insurance companies. Constellation sees transparency and ML/AI explainability as something that organizations and industries will demand as we embrace predictive and prescriptive systems that recommend and automate decisions. There have been plenty of examples where biases have been discovered in decision systems that impact people’s lives.
MyPOV on Reinvent Overall
Once again, re:Invent was impressive, and the sheer number of announcements was stunning. I could site at least a dozen other notable data-to-decisions-related announcements, from AWS IoT Analytics to Amazon Translate (real-time translation) to Rekognition Video (object/activity/face detection) to Polly Transcribe (real-time, multi-language transcription). To Jassy’s point, having everything one could possibly need probably is everything to a developer. But when is enough enough?
My point is not to eliminate services and take away capabilities, but AWS CTO Wener Vogels pointed out in his keynote that the company has released a whopping 3,951 new services and capabilities since the first re:Invent event in 2012. The sheer number has sometimes been “confusing and hard to deal with,” Vogels admitted. He went on to talk about the administrative tools and services that Amazon has come out with to ease cloud architecture, development, deployment, operational management and cost/performance optimization. This includes everything from CloudFormation, CloudWatch, Config, and CloudTrail to Config Rules, Cost Explorer, Inspector and Trusted Advisor.
So, yes, AWS is doing a lot to make working on the platform simpler, easier and more cost-effective, but I’ll close with three proposals to shift the emphasis and communications agenda a bit at re:Invent 2018.
Put the emphasis on improving existing services. Wherever possible, build on existing services rather than introducing yet another service. DynamoDB Global Tables, Backups and On-Demand Restore, for example, are examples of new features added to one of AWS’s oldest services. Werner Vogels noted that AWS likes to get new services out there even if it knows that certain features are wanting. That way it can get customer feedback on how to improve the service. I would submit that AWS is now so large, it would do well to add value to existing services first and take more time to polish new services before introducing them. I’d also make a point of highlighting upgrades to existing services at re:Invent so customers recognize the growing value of services already in use.
Put management and administrative services in the spotlight. This year there were a whopping 61 new product announcements overall at re:Invent, yet only two in the “Management” category: AWS Systems Manager and a new logging feature added to AWS CloudTrail. Systems management may not be as sexy as a new AI or ML service, but AWS should make point of using re:Invent to announce and highlight new capabilities that will help companies spend less, simplify, save employee time and get more bang for the buck. It may be that AWS Systems Manager didn’t get much limelight at re:Invent because it seems to be a makeover of Amazon EC2 Systems Manager, introduced at re:Invent 2016. According to a blog on the new AWS Systems Manager, it “defines a new experience around grouping, visualizing, and reacting to problems using features from products like Amazon EC2 Systems Manager.” As the scale of AWS grows and companies use more and more services, I would think management tools and services would keep pace and take advantage of the most advanced technologies AWS is applying in other areas.
Bring more automation and AI to building and management capabilities. Following up on the last point, I was really intrigued by Werner Vogel’s discussion of the AWS Well-Architected Framework and Well-Architected Principles, but everything under this category seems to about white papers, best-practice documents, and case studies. That’s all great, but I sense an opportunity to turn this content into helpful services or, better still, new advisory features embedded into existing services. Point the sexy stuff, like machine learning and AI, at how customers use AWS and surface recommendations at every stage of development, deployment and operations. That seems to be the focus of some of the automation tools mentioned above, but let’s see more. Maybe even embed some of these capabilities directly within tools and services so it’s not up to administrators and managers to fix bad practices. These are areas where AWS should excel. If you help customers use AWS well and cost effectively, they will be even happier and more loyal than they are today.
Related Reading:
Salesforce Dreamforce 2017: 4 Next Steps for Einstein
Oracle Open World 2017: 9 Announcements to Follow From Autonomous to AI
Microsoft Stresses Choice, From SQL Server 2017 to Azure Machine Learning

