
MapR promises a more scaleable, reliable, real-time-capable and converged alternative to Hadoop, NoSQL databases and Kafka combined. Are companies buying it?
MapR is frequently mentioned in the same breath with Hadoop vendors Cloudera and Hortonworks, but maybe it’s time to stop thinking of them as competitors. Indeed, over the last eighteen months, MapR has added ambitious NoSQL database and streaming capabilities to what the company now calls its MapR Converged Data Platform.
The differences between MapR and its erstwhile competitors were underscored at MapR’s first ever analyst day, December 13, at its headquarters in San Jose, CA. Executives not only contrasted MapR’s platform with Hadoop, it also detailed advantages verses NoSQL databases Cassandra, HBase and MongoDB, and an open source staple of streaming applications, Apache Kafka. They bemoaned the “complexity” and “chaos” of multi-project open-source deployments, and MapR CEO Matt Mills, a 20-year Oracle veteran, proudly declared MapR to be “a commercial enterprise software company.”
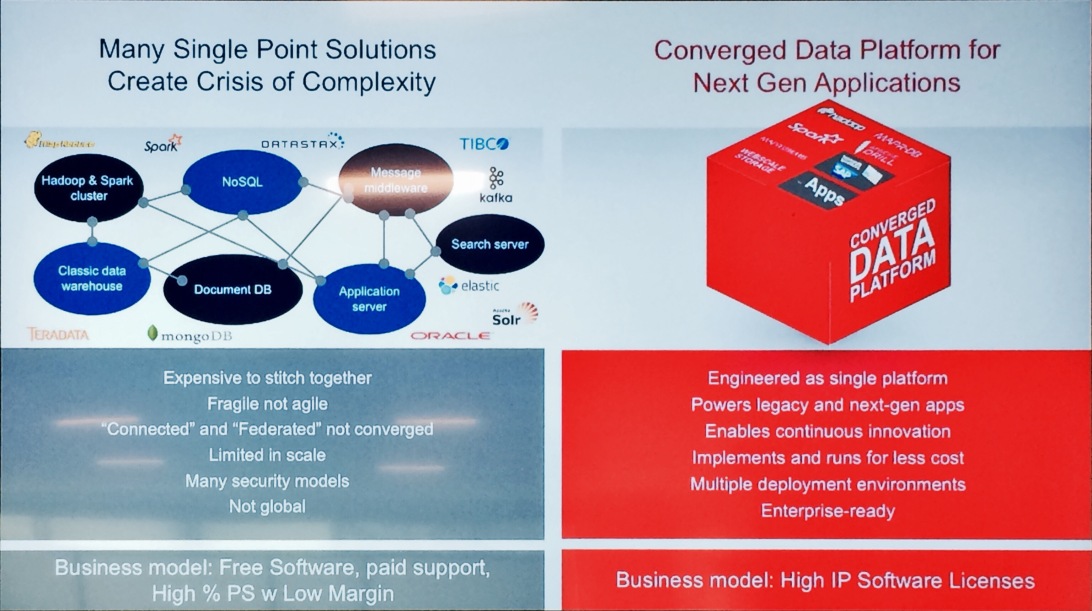
MapR presents its Converged Data Platform as a more scalable, reliable and performant
alternative to Hadoop, NoSQL databases and other big data tools.
It’s not that MapR doesn’t exploit open source innovation. The MapR platform includes components of Hadoop and Spark as well as Drill and Myriad, the last two being projects incubated by MapR and contributed to open source. The platform also relies entirely on industry-standard and open source APIs (a choice the company asserts eliminates the possibility of lock-in), even when MapR has replaced the associated components.
MapR chose from its founding to replace the Hadoop Distributed File System (HDFS) with a POSIX/NFS standard file system, for example, yet developers can still use the HDFS API. The POSIX/NFS choice provided read/write capabilities (verse append-only HDFS), better performance, and a “volumes” data construct for higher scalability and easier data organization and governance.
The early POSIX/NFS choice is now paying dividends as MapR goes after database and streaming rolls. The underpinning technology gives the MapR-DB database consistency, reliability and scalability advantages over HBase, Cassandra and MongoDB, says the company, yet developers can still use the HBase API. And given the breadth of capabilities across the platform (including MapR-DB), MapR cites scalability, data persistence, performance and global deployment advantages over Kafka and complex Lambda architectures (yet developers can use the Kafka API).
MapR hasn’t brought together all these capabilities just to check more boxes. Executives said they’re seeing more and more customers building out next-generation applications. The hallmark of such applications is compound requirements spanning the capabilities of file systems, search, databases and streaming systems. Another trait is the embedding of analytics directly into operational applications to support automated, data-driven actions without human intervention. MapR says its converged platform supports all of these demands with better speed, scale and reliability than you can cobble together with multiple open-source point systems.
MapR shared plenty of examples of customers building out next-gen apps. A Paysafe executive was there to talk about how it detects potentially fraudulent payment transactions within milliseconds so it can stop them before they go through. Rubicon runs a real-time, high-scale online ad exchange that handles peak loads of 5 million queries per second with 300 real-time decisions per ad placement. National Oilwell Varco analyzes sensor data from its oil well drills in real time to optimize production output and support predictive maintenance. And Qualcomm monitors sensors in its semiconductor plants in real time to automate actions that improve manufacturing yields.
The typical MapR customer is experienced with big data deployments, and more than 40% are former Cloudera or Hortonworks customers, according to the company. Given MapR’s commercial approach and emphasis on sophisticated requirements, it’s not the right choice for a big data newby or an open-source zealot. Partner Gustavo De Leon of Cognizant described would-be MapR customers as falling into the second of two classes of big data practitioners he’s seeing. First, there are the companies doing lots of big data proof-of-concept (POC) projects and not being terribly productive. Second, there are the companies that are more business focused that a concentrating on specific use cases.
De Leon’s implication was that MapR customers “want to know that they can take POCs into production and that the application will be enterprise ready and capable when they’re done.”
MyPOV on MapR Converged Data Platform
MapR’s foray into NoSQL and steaming opportunities is ambitions but the vision to serve converging requirements and high-performance demands isn’t new to the company. It has been the company’s focus and direction for years. What was new at the analyst day was hearing the vision directly from top brass along with forward-looking statements about the roadmap, investment plans and a possible future initial public offering. What was somewhat surprising was hearing quite the degree of open-source bashing, though I am hearing growing impatience from big data practitioners about the complexity of deploying and managing dozens of separate open source projects.
It was a good first-time analyst event for MapR, but the company was a bit stingy with company measures and plans. The roadmap was more like a set of themes with no precise dates attached. I also would have liked to hear from more customers, including non-OEM customers who don’t have an interest in promoting their own business. MapR has a solid list of high-profile customers, but it’s understandably hard to get an executive from an American Express, Audi, Novartis or United Healthcare to come speak at a tiny insider event in mid December.
Given MapR’s comparatively small size (which it doesn’t disclose but is likely somewhere between $100 million and $200 million), I would have liked to have heard a more nuanced, flexible positioning in the “land-and-expand” or “we can work with incumbent tools or replace them” vein. Instead we heard the hard-sell “we can do it all and do it better than all those other [popular and widely used] tools out there.” I’m guessing that in real-world sales situations there are plenty of developers and influencers predisposed to popular open source choices. I’m also guessing MapR has an easier time making a case for its converged story once it’s established inside a company. And no doubt it gets the nod first as a big data analytics platform, and not as a stand-alone NoSQL database or streaming choice.
I completely agree with MapR that people have to stop thinking of analytics only as reports, data visualizations and other types of human interactions and start thinking more about embedding analytics into transactional applications as automated triggers and actions. At the very least it should be alerts for exception conditions. As companies move toward these sorts of sophisticated, next-gen applications, MapR will have a better and better shot at being part of the conversation.
Related Reading:
Strata + Hadoop World Highlights Long-Term Bets on Cloud
Hadoop Hits 10 Years: Growing Up Fast
Strata + Hadoop World Report: Spark, Real-Time In the Spotlight

![]()

