
Nvidia CEO Jensen Huang poked holes in all the arguments against the company during the company's third quarter conference call. Concerns about power, costs, LLMs hitting a wall and hyperscale cloud providers digesting all the GPUs already acquired were all brush aside.
Yes folks, Huang has a dream. In this dream, Nvidia demand remains insatiable until $1 trillion worth of data centers are upgraded for the AI age. See: Nvidia strong Q3, sees Hopper, Blackwell shipping in Q4 with some supply constraints
In this dream...
- Nvidia platforms continue to make exponential gains that cut costs, keep competition at bay and warrant a premium due to price for performance.
- LLMs will continue to scale and improve without a plateau.
- Cloud service providers that are accounting for Nvidia's data center growth don't pause to digest existing purchases. “I believe that there will be no digestion until we modernize a trillion dollars with the data centers,” said Huang.
- All companies will be in the inference game and generating tokens that add to data to train AI.
- AI factories will solve the looming energy and sustainability problems.
- And if the GPU growth plateaus, Nvidia can offset with networking, robotics, automotive and quantum.
In many ways, Huang sounded like an NFL coach that listens to sports talk radio, doesn't necessarily admit to tuning in, but aims to rebut fan arguments. Much of what Huang said on Nvidia's earnings call was designed in part to offset concerns that are bubbling up even though the financials remain stellar.
Huang concluded Nvidia's earnings call with the following:
"The age of AI is upon us and it's large and diverse. Nvidia's expertise, scale, and ability to deliver full stack and full infrastructure let us serve the entire multi-trillion dollar AI and robotics opportunities ahead. From every hyperscale cloud, enterprise private cloud to sovereign regional AI clouds, on-prem to industrial edge and robotics."
I ran the Nvidia transcript on OpenAI to assess sentiment and the result was "overwhelmingly positive." The word cloud looked like this.
Let's take on the Huang AI dream and address by key parts.
Costs. Huang has been consistent with its take that Nvidia systems are becoming more efficient and driving total cost of ownership gains.
On the third quarter conference call, cost of compute, training and inference was addressed about 10 times on par with the second quarter and at a Q&A at a Goldman Sachs investment conference in September.
Huang said:
"We're on an annual roadmap and we're expecting to continue to execute on our annual roadmap. And by doing so, we increase the performance, of course, of our platform, but it's also really important to realize that when we're able to increase performance and do so at X factors at a time, we're reducing the cost of training, we're reducing the cost of inferencing, we're reducing the cost of AI so that it could be much more accessible."
My take: For now, Huang isn't wrong. The efficiency gains in Nvidia's software stack and platforms are impressive. However, there will be a point--likely starting in 2025--where good enough will work. It shouldn't be overlooked that all of the hyperscalers are developing their own AI accelerators and diversifying with AMD and others.
LLMs capabilities stalling? Questions about LLMs continuing to scale spurred a dissertation from Huang. After all, if training techniques hit a wall so does the FOMO driving Nvidia sales.
He said:
"Foundation model pre-training scaling is intact and it's continuing. As you know, this is an empirical law, not a fundamental physical law, but the evidence is that it continues to scale. What we're learning, however, is that it's not enough that we've now discovered two other ways to scale. One is post-training scaling. Of course, the first generation of post-training was reinforcement learning human feedback, but now we have reinforcement learning AI feedback and all forms of synthetic data generated data that assists in post-training scaling."
Huang said OpenAI ChatGPT o1 is an example of how LLMs haven't hit a plateau. "We now have three ways of scaling and we're seeing all three. And because of that, the demand for our infrastructure is really great," he said.
My take: It's unclear whether LLMs will advance at the current pace. Enterprises may also leverage LLMs that are cheaper to train and tailor. Even a yearlong pause in LLM gains could trip up Nvidia's ability to hit already inflated expectations.
- Softbank Corp. first to land Nvidia Blackwell systems in bid to be genAI provider in Japan
- Nvidia drops NVLM 1.0 LLM family, revving open-source AI
Cloud service providers (CSPs) are going to continue to spend like drunken LLM trainers. Huang said:
"All of these CSPs are racing to be first. The engineering that we do with them is, as you know, rather complicated. And the reason for that is because although we build full stack and full infrastructure, we disaggregate all of the AI supercomputer and we integrate it into all of the custom data centers in architectures around the world. That integration process is something we've done for several generations now. We're very good at it, but still, there's still a lot of engineering that happens at this point. But as you see from all of the systems that are being stood up, Blackwell is in great shape."
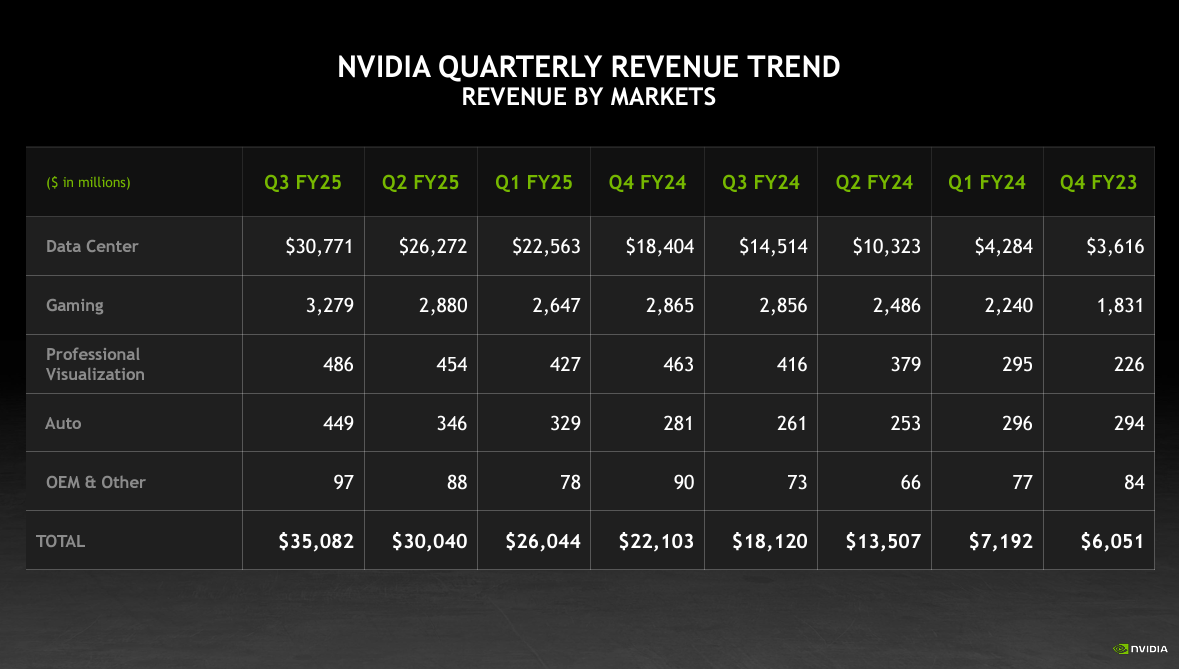
Nvidia said half of its data center revenue was cloud service providers, but the other half was consumer internet and enterprise. I'm guessing that other half is dominated by Meta.
My take: The argument that CSPs won't pause spending is tenuous. History rhymes and I doubt this time is different as AI infrastructure is built out.
- AI data center building boom: Four themes to know
- Is AI data center buildout a case of irrational exuberance?
- The art, ROI and FOMO of 2025 AI budget planning
- The generative AI buildout, overcapacity and what history tells us
- GenAI's 2025 disconnect: The buildout, business value, user adoption and CxOs
All inference all the time. Huang talked up the agentic AI game, noted AI Enterprise revenue is going to double over the year. Huang said:
"We're seeing inference demand go up. We're seeing inference time scaling go up. We see the number of AI-native companies continue to grow. And of course, we're starting to see enterprise adoption of agentic AI that really is the latest rage. And so, we're seeing a lot of demand coming from a lot of different places."
My take: In Huang's dream, every time you open a PDF or PowerPoint you'll generate tokens at the edge. These inputs will continue to drive models forward. Huang is on target, but we may be debating about the timing of this inference nirvana for years.
Energy and sustainability. Huang said continued efficiency gains from Nvidia systems will alleviate concerns about energy consumption.
Huang said data centers are moving from 10s of megawatts to 100s of megawatts to ultimate gigawatts. "It doesn't really matter how large the data center is, power is limited," he said. "Our annual roadmap reduces cost, but because our perf per watt is so good compared to anything out there, we generate for our customers the greatest possible revenues."
My take: The biggest issue here isn't performance per watt, but sourcing the power. The grid is tapped and innovations like small nuclear reactors are years from scaling. Nvidia isn't going to improve performance per watt so much that it'll have no impact on power consumption.
Nvidia has plenty of other innovations on the runway. Huang noted that Nvidia is growing its software, networking, robotics and automotive businesses. He said:
"There's a whole new genre of AI called physical AI. Physical AI understands the physical world and it understands the meaning of the structure and understands what's sensible and what's not. That capability is incredibly valuable for industrial AI and robotics."
- Nvidia outlines Google Quantum AI partnership, Foxconn deal
- On-premises AI enterprise workloads? Infrastructure, budgets starting to align
My take: The reality is that Nvidia's data center business is carrying the company. However, Nvidia is well positioned for the next big thing--including quantum.
- Nvidia's uncanny knack for staying ahead
- Nvidia highlights algorithmic research as it moves to FP4
- Nvidia launches NIM Agent Blueprints aims for more turnkey genAI use cases
- Nvidia shows H200 systems generally available, highlights Blackwell MLPerf results
- Nvidia outlines roadmap including Rubin GPU platform, new Arm-based CPU Vera

