
Generative AI models are going to have a big training data issue as public web access becomes more restricted and it's unclear whether large language models (LLMs) will be able to avoid the garbage in, garbage out issue.
This data access issue is just getting started, but there's enough developing to see the wall ahead. Constellation Research CEO Ray Wang has said that the open web will largely disappear as content providers and corporations restrict data access. If this scenario plays out, LLMs aren't going to have the training data available to continually improve.
“We will not have enough data to achieve a level of precision end users trust because we are about to enter the dark ages of the internet, where the publicly available information on the internet will be a series of Taylor Swift content, credit card offers, and Nvidia and Apple SEO. Where will the data come from?” said Wang.
- 14 takeaways from genAI initiatives midway through 2024
- Meet Data Inc. and what a post AI company looks like
- GenAI, originality and scaling lookalikes
Here are a few developments that have me wondering about the data wall we're going to hit.
Cloudflare last week announced a new feature for its customers that would prevent AI bots from scraping data from sites. There has long been a robots.txt standards that prevents information from being indexed by search engines. The general idea was that the robots.txt approach would also give creators the ability to prevent content from being used for LLM training data.
The reality is that the AI bots are blowing right past that robots.txt approach. Cloudflare's post on disabling AI bots is worth a read. A few highlights include:
Bytespider, Amazonbot, ClaudeBot, and GPTBot are the top four AI crawlers. Bytespider is run by Bytedance, the parent of TikTok. "We hear clearly that customers don’t want AI bots visiting their websites, and especially those that do so dishonestly. To help, we’ve added a brand new one-click to block all AI bots," said Cloudflare.
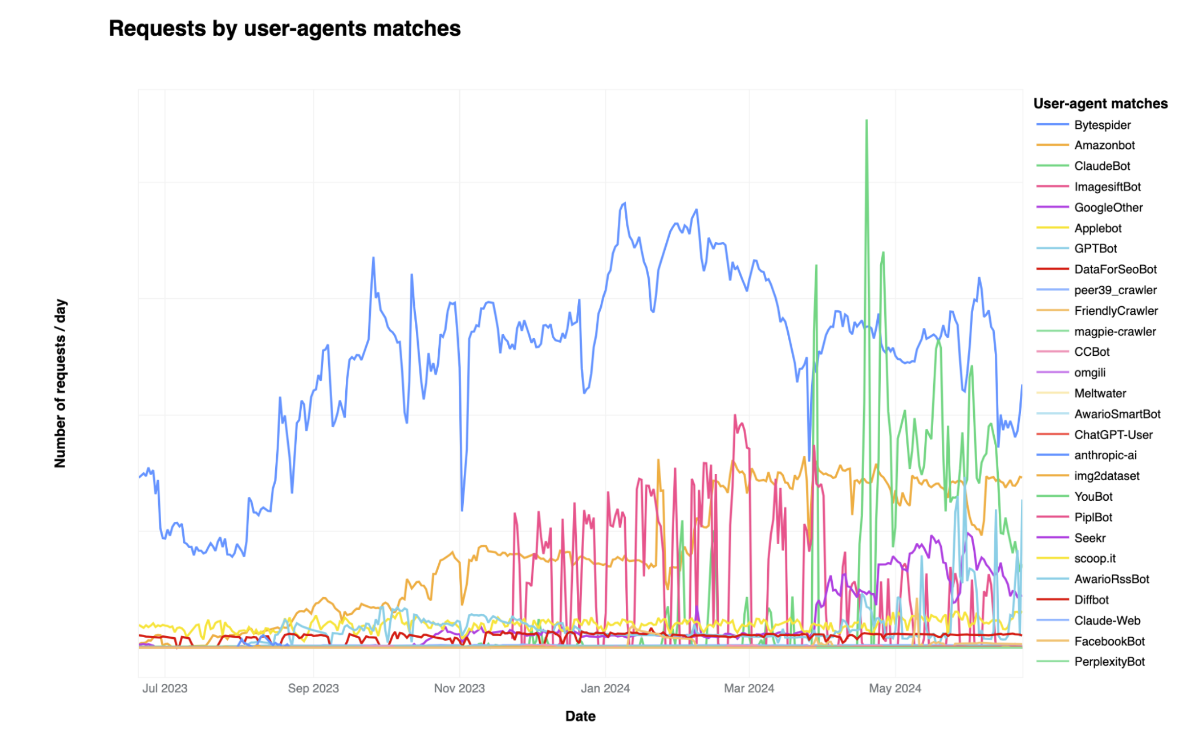
If you play this out, you can rest assured that the most credible sites are going to block AI bots. After all, why give the content away that you can license? Google licensed Reddit content. Media giants are pairing up with Google or OpenAI.
Reddit laid out the open internet meets AI conundrum in May:
"We see more and more commercial entities using unauthorized access or misusing authorized access to collect public data in bulk, including Reddit public content. Worse, these entities perceive they have no limitation on their usage of that data, and they do so with no regard for user rights or privacy, ignoring reasonable legal, safety, and user removal requests. While we will continue our efforts to block known bad actors, we need to do more to restrict access to Reddit public content at scale to trusted actors who have agreed to abide by our policies."
This potential data wall for genAI is so critical that synthetic data is becoming increasingly important. The general idea behind synthetic data is that models will generate content that will then be used to train future models.
Last month, Nvidia released Nemotron-4 340B, a family of models optimized for Nvidia NeMo and TensorRT-LLM, to advance synthetic data. Nvidia CEO Jensen Huang has a vision that includes AI factories creating data and then learning from it to create more models.
That Nvidia synthetic data vision only works if there's a continuous stream of quality data to ingest. Companies like Google and Meta have those streams since users create data every second. Most LLM players won't have that access and will aim to avoid licensing.

Add it up and we may see a reverse data flywheel. More creators pull data and content from the open web. LLMs train on what's available. You get what you pay for, so the data is crap. Then these models trained on crap data train more models. If this data quality issue doesn't get sorted out, the only thing generative AI is going to scale is crappy models.

