
Amazon Web Services Re:Invent 2020 continues the vendor’s tradition of delivering a slew of announcements. Here’s my take on the top data-to-decisions introductions.
Where to begin to size up the more than 35 announcements slated for just the first week of Amazon Web Services (AWS) #ReInvent 2020? Guided by my data-to-decisions (D2D) research focus, let’s drill down on what I see as the highlights among the database, machine learning, and intelligent edge/IoT announcements from week one of this three-week virtual event.

Amazon Web Services CEO Andy Jassy kicking off Re:Invent 2020.
(I’ll skip over all the new compute and storage instance types as well as the container-management, serverless computing and hybrid deployment announcements. Not that these offerings won’t have big impacts on D2D deployments -- they most certainly will -- but the highlights will, no doubt, be covered in detail by my colleague, Holger Mueller.)
‘Glue’ing Together the Database Services
AWS’s database strategy is to deliver a fit-for-purpose service for every need, as exemplified by Amazon RDS (relational database services), DynamoDB key value store, Amazon ElastiCache in-memory store, Amazon Neptune graph database, Amazon DocumentDB, and the Amazon TimeStream time-series database. AWS says customers want “the right tool for the right job to optimize their workloads.”
In contrast, AWS rival Oracle emphasizes that graph, JSON (document), and time-series capabilities are all built into its flagship Oracle Database. But the success of role-specific databases (from AWS and others) strongly suggests that there are many cases where the performance and depth and breadth of functionality from task-specific products and services matters. The downside of using separate services is that you can end up with silos of data. This problem triggered what I see as the most significant database-related announcement from Re:Invent:
- AWS Glue Elastic Views. This new service, in preview as of December 1, is designed to automatically combine and/or replicate data across multiple data stores, creating a virtual table (or materialized view) in a target data store. You could, for example, combine data from multiple stores and copy it into Redshift for analytical use or ElastiSearch for searching. AWS Glue Elastic Views monitors source stores and updates the target automatically “within seconds,” according to AWS. The preview works with DynamoDB, S3, Redshift and ElastiSearch, and support for Aurora is said to be on the roadmap. MyPOV: The longer the “works with” list becomes, the more powerful and attractive this feature will be. Customers will undoubtedly clamor for Aurora support and other RDS options.
Here are two other notable database-related Re:Invent week one announcements:
- Amazon Aurora Serverless v2. This advance over Serverless v1 is touted as brining greater elastic scalability as well finer-grained (cost-saving) scaling increments to Aurora. MyPOV: Elastic, serverless scaling is big cost saver as compared to conventional provisioning for peak workloads. Customers asked for, and are now getting, capabilities for more demanding Aurora deployments through Serverless v2.
- Babelfish for Amazon Aurora PostgreSQL. Don’t let the name confuse you: Aurora already offered PostgresSQL “compatibility.” Babelfish is a new translation layer, in preview as of December 1, that will enable Aurora PostgreSQL to understand Microsoft SQL Server T-SQL. Babelfish enables applications built using T-SQL to “run with little to no code changes,” according to AWS. The goal is obviously to accelerate migrations from Microsoft SQL Server to Amazon Aurora. Once moved, you would write to PostgreSQL. MyPOV: Keep in mind that AWS database “compatibility” (be it Aurora with PostgreSQL or MySQL, Keyspaces with Apache Cassandra, DocumentDB with MongoDB or, now, Aurora PostgreSQL with Microsoft SQL Server) is a one-way proposition. Once you migrate, you are running on an AWS database service and there’s no easy migration path back to the database you formerly used. Be sure you will be fine with the reality that there’s no easy way to go back.
Filling in the SageMaker Gaps
AWS made huge strides forward on the ML front over the last year with the introduction of SageMaker Studio (based on JupyterLab), SafeMaker Autopilot, SageMaker Debugger, SageMaker Model Monitor and more – all announced at Re:Invent 2019. At Re:Invent 2020 AWS plugged some of the few remaining holes:
- SageMaker Data Wrangler is, as the name suggests, a self-service data-prep option that will enable a broader base of users (not just data engineers) to handle the data cleansing and transformation tasks that are necessary before you attempt to build reliable models. The tool set promises to make data-prep workflows repeatable and automated. MyPOV: Obvious and overdue, but, nonetheless, welcome. I’m eager to hear more about the depth and breadth of capabilities.
- SageMaker Feature Store is aimed at getting more mileage out of the work that goes into feature engineering. As with any good repository, this service is designed to help you store, discover and share – in this case features for use across multiple ML models. It’s also said to help with compliance requirements, as you can recreate features at a point in time. MyPOV: Data science skill is scarce, so any advantage available in reusability and productivity is welcome.
- Amazon SageMaker Pipelines is designed to build automated ML workflows at scale, cutting development-to-deployment time from “months to hours,” according to AWS. These automated pipelines are said to be easily auditable because model versions, dependencies and related code and artifacts are tracked. MyPOV: Automation is the key to bringing ML into production at scale, so this is a welcome announcement.
Improving Industrial Processes With Edge Intelligence
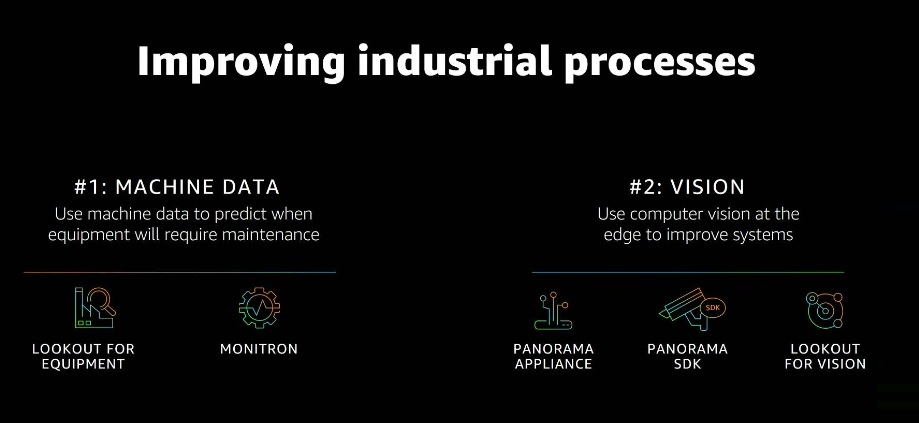
Machine learning and machine vision are the core of four new industrial IoT services introduced by AWS:
- Amazon Lookout for Equipment is an ML-based anomaly detection service for industrial equipment. In preview as of December 1, this service is focused on predictive maintenance for assets such as motors, pumps, turbines and more.
- Amazon Monitron is a complete, end-to-end monitoring system for industrial assets that includes sensors, a gateway device and ML services to detect abnormal conditions. Now generally available, Monitron also includes a prebuilt mobile app that tracks the status and health of assets without the need for mobile app development or model training.
- AWS Panorama is a small-footprint appliance that’s installed locally to run custom computer-vision models at the edge for real-time decisions in applications such as quality control, part identification and workplace safety. Now in preview, AWS Panorama includes a software development kit designed to support pre-existing or Panorama-compatible camaras, integrate with AWS ML services, and support model development and training in SageMaker.
- Amazon Lookout for Vision is used to develop models to spot defects and anomalies using computer vision and can be used at the edge in conjunction with the Panorama appliance. Computer vision models used to detect damage, evaluate color, identify missing components and other machine vision inspection needs can be trained with as few as 30 images, according to AWS.
MyPOV on Industrial Advances: Predictive maintenance and quality control are the most in-demand, starting-point applications in IoT and machine vision deployments, respectively. AWS has formidable competition on these fronts from Microsoft Azure, so getting more industrial customers in at the top of the funnel by lowering time-to-value for high-demand applications is an important objective. The IoT arms race is far from over, and AWS is also this week introducing improvements to its Marketplace that will make it easier for customers to work with third-party IoT partners and service providers.
MyPOV on Re:Invent 2020
The rule of thumb for many virtual tech event organizers in 2020 has been to cut down on the presentation time and the volume of keynote content that would have otherwise been delivered in an in-person event. The idea is that virtual attention spans are virtually nonexistent, but AWS apparently didn’t hear or heed the advice on timing. AWS CEO Andy Jassy’s opening Re:Invent keynote once again clocked in at nearly three hours.
As for the content, AWS once again delivered a juggernaut of new product introductions and announcements in just the first week, but qualitatively, the announcements -- at least those in the database and ML arenas - don't feel as substantial as those in 2019. As noted above, AWS delivered quite a bit last year, so the approach of filling in gaps and introducing v2 improvments is likely to be welcome to cutomers, many of whom are still adjusting to working with remote teams and trying to make the most of the AWS services already in use. In fact, in years past, I've encouraged AWS to focus more on quality, fit and finish and less on the quantity of Re:Invent announcements. Also on the topic of making the most of what's already available, I really like some AWS Marketplace announcements, coming later this week, that will make it easier to work with third-party software and service providers in Amazon's cloud.

