
Hortonworks customers Ford, Macy’s and Progressive Insurance highlight breakthrough applications. Streaming looms as next big thing in big data.
Plenty of companies have mastered their first-generation uses of Hadoop. Now they’re scaling up and going after more sophisticated applications.
That’s the state of big data that emerged at the June 28-30 Hadoop Summit in San Jose, CA. Hosted by Hortonworks and Yahoo, the 4,000-attendee event was peppered with presentations by customers including Progressive Insurance, Macy’s, Ford, BlueCross BlueShield of Michigan and ConocoPhillips. The event also highlighted announcements by Hortonworks, the company’s cloud partnership with Microsoft on Azure HDInsight, and a rich track on emerging streaming data applications.
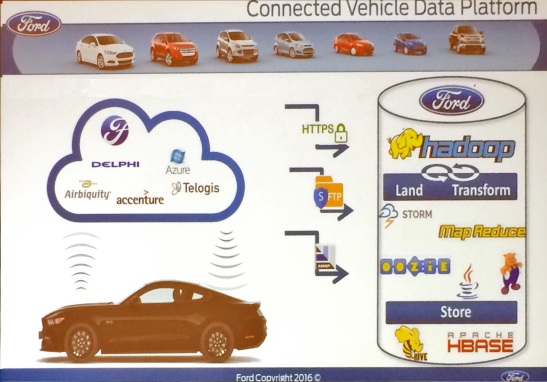
Ford detailed its Hadoop-based connected car data platform at Hadoop Summit and explained
how it works with the FordPass mobile app.
Most Hadoop Summit attendees seem intent on learning from peers. Here’s a quick sampling of the real-world use cases presented.
Blue Cross Blue Shield of Michigan is building out what Beata Puncevic described as the company’s “next-generation data platform with Hadoop at the center. Puncevic, director of analytics, data engineering and data management, said the effort is bringing together disparate data silos spanning multiple generations of technology including mainframe apps. Schema-on-read flexibility is improving cost efficiencies and time to data delivery, she said, and an early analytical win has been faster and deeper insight into drug prescription trends.
ConocoPhillips has been using Hadoop for about a year and the first win was cost avoidance on the company’s conventional data warehousing platform, said Kelly Cook, the company’s director of analytic platforms. By moving ETL workloads, archival data and high-scale sensor data from oil and gas wells to Hadoop, the company has avoided what Cook called “hugely expensive” investments in data warehouse capacity in favor of “a lot less expensive” Hadoop capacity. Given low energy prices over the year or more, ConocoPhillips is under pressure to keep costs down.
Progressive Insurance built its well-known Snapshot usage-based auto-insurance offering on top of Hadoop. The company has compiled more than 15 billion miles worth of driving data from Snapshot devices that plug into auto diagnostic ports and relay data from insured vehicles. By assessing factors such as miles driven, nighttime driving, speed and breaking events, Progressive can offer discounts to drivers who demonstrate safe driving habits. In a keynote presentation, Progressive’s Brian Durkin, innovation strategist, and Pawan Divakarla, business leader, data and analytics, described how the company can drill down through petabytes of data to get to policy-specific pricing decisions.
Macy’s started using Hadoop some five years ago to understand online purchasing habits on Macys.com. That entailed analyzing Web and mobile clickstreams and overlaying product, customer and preference data. Macy’s is now doing more sophisticated analyses of customer journeys from Macy.com to store visits and vice versa. That has helped the company target messages to online customers to encourage them to buy in stores and it encourages in-store customers to try shopping online. Macy’s is now piloting Beacon mobile sensor technology to drive near-real-time insight. The company is testing detecting the presence and location of Macy’s mobile app users within stores and then deliver offers instantly based on recent online and in-store browsing and buying activity. If you were browsing swimsuits in recent days, a message delivered when you arrive at the store might direct you to sportswear and offer a discount.
Ford runs its FordPass connected car app on the Hortonworks Hadoop stack. It’s an early example of an IoT-style application where data is used in different ways at different locations on the network. A Ford Fusion hybrid vehicle generates as much as 25 gigabytes of sensor data per hour, so Ford does plenty of filtering at the edge of the network (meaning in the car) so that only the data that’s needed is sent back to centralized systems. For example, FordPass users can remotely check their car’s fuel level and see diagnostic error codes, but the detailed diagnostic data used by service technicians stays in the car.
The level of insight varies by application, and owners have to opt in to share their data. In commercial fleet applications, owners typically want continuous geolocation information so they can see where their vehicles are at all times. In the case of individual consumers, Ford captures location data only the key is turned on and off. The latter enables FordPass users to find their parked car in massive parking lots.
In internal uses of data, Ford analyses aggregated diagnostic codes by model and year to spot possible defects and improve warranty support. Ford is also correlating vehicle data with social data to help product development team understand what people are saying about features and performance characteristics.
Hortonworks Talks Cloud, Streaming
Hortonworks announced the latest release of the Hortonworks Data Platform (HDP) at Hadoop Summit, and it also put a spotlight on its longstanding cloud partnership with Microsoft on Azure HDInsight. HDP 2.5, due out in the third quarter, will include Apache Atlas upgrades including data-classification and metadata tagging, for fine-grained governance and security control. The distribution will also include Apache Zeppelin software for notebook-style data analysis and visualization integrated with Apache Spark.

Microsoft executive Joseph Sirosh talked about the “unreasonable effectiveness” of the new
ACID — algorithms, cloud, IoT and data — to tackle big problems.
Growing interest in cloud and hybrid deployment has been the buzz at most big-data-related events this year. It was a central theme at Cloudera Analyst Day, the Teradata Influencer Summit, and at MongoDB World, June 27-28, where the company announced its MongoDB Atlas cloud service.
Hortonworks reminded Hadoop Summit attendees that it was very early to the cloud through its partnership with Microsoft to develop the HDInsight Service on Azure, which dates to 2012. Based on HDP, HDInsight is a managed, public cloud service (much like Amazon Elastic MapReduce), so all administration is handled by Microsoft. This is attractive to the many customers, particularly newcomers, who don’t want to deal with deploying and managing a Hadoop distribution on public cloud infrastructure services.
Hortonworks also talked up the growing interest in streaming data use cases at Hadoop Summit. That naturally led to descriptions of the Hortonworks Data Flow (HDF) platform, which is based on Apache NiFi. There were plenty of sessions on streaming data at Hadoop Summit, but the vast majority were given by vendors. Streaming data analysis is commonplace in financial trading, national security and certain advertising and e-commerce circles, but it’s early days for mainstream use cases.
MyPOV on Hadoop Summit
Hortonworks’ announcements at Hadoop Summit were incremental. The Atlas upgrades are certainly welcome and necessary, but I don’t get too excited about basics of security and access control that enterprises just expect to be there. The Zeppelin Web-based notebook interface is more interesting, as it promises to open up access to business users, simplifying analysis and data visualization in conjunction with Spark.
Hortonwork’s HDInsight plug was more or less a reminder that it has the public cloud option covered through its Microsoft partnership. But Azure isn’t the only cloud out there. Hortonworks last year introduced CloudBreak, its cloud-deployment tool, in the HDP 2.3 release. I didn’t hear anything about new CloudBreak capabilities or cloud deployment uptake, so my guess is that Hortonworks is preoccupied with other priorities.
Finally, I agree that streaming is shaping up as a next big thing in data management and analytics, but I’d advise newbies to start experiments with streaming-capable tools that may already be at their disposal, like HBase, Kafka and Spark. I’d get a taste of streaming challenges and consider the breadth of opportunities before adding a system like HDF. I like HDF’s drag-and-drop approach to developing dataflows, but it’s akin to adding a factory for streaming data use cases. If you have just a few, it might be overkill.
I was most impressed by the list of companies presenting at Hadoop Summit. It was also good to that the number of traditional enterprises (BlueCross BlueShield of Michican, CapitalOne, ConocoPhillips, Ford, Macy’s, Merck, Progressive Insurance, Schlumberger) was on par with the number of Internet companies (eBay, Facebook, LinkedIN, Netflix, PayPal, Uber, Yahoo). That tells me that Hadoop is settling in as the next-generation enterprise data-management platform.

![]()

