
The large language model (LLM) industry is racing to rid themselves of glaring weaknesses that hamper broader use cases.
OpenAI released a paper designed to improve legibility and verification so humans can better evaluate them. In a nutshell, OpenAI researchers pitted models against each other via a "Prover-Verifier" game that enhanced the ability for LLMs to show their work.
In a blog post, OpenAI said:
"We found that when we optimize the problem-solving process of strong models solely for getting the correct answer, the resulting solutions can become harder to understand. In fact, when we asked human evaluators with limited time to assess these highly optimized solutions, they made nearly twice as many errors compared to when they evaluated less optimized solutions. This finding highlights the importance of not just correctness, but also clarity and ease of verification in AI-generated text."
OpenAI then deployed the prover-verifier games that involve one model that generates a solution and another verifier that checks for accuracy. The goal was to ensure answers were right and make them easier to verify by humans and other models.

According to OpenAI, the ability to verify answers will improve trust and pave the way for autonomous AI systems. The methodology from OpenAI is just a first step and models still require grounding.
Mistral AI also released Mathstral, a model that's designed to "bolster efforts in advanced mathematical problems requiring complex, multi-step logical reasoning."
In a blog post, Mistral AI said Mathstral is built on Mistral 7B but specializes in STEM subjects. The company added that Mathstral highlights the benefits of building models for specific purposes.
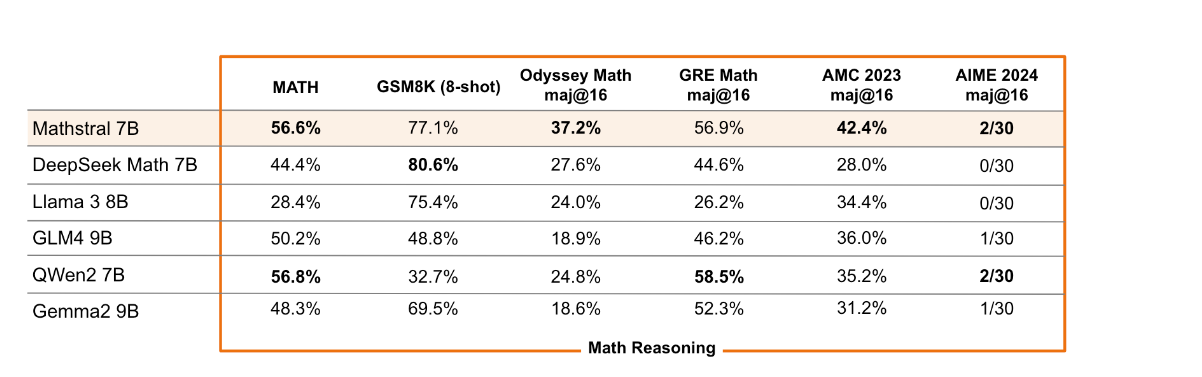
Mathstral, which is released under an Apache 2.0 license, outscored most models on math reasoning.
With developments moving quickly it's clear that LLM creators are quickly looking to enable more complex problem solving that'll benefit enterprises.

