
Nvidia said its H200-powered systems are generally available and will launch on CoreWeave as the first cloud service provider and server makers including Asus, Dell, HPE, QTC and Supermicro.
The general availability comes as Nvidia released MLPerf Inference v4.1 benchmarks for its Hopper architecture and H200 systems and its first Blackwell platform submission.
- Nvidia highlights algorithmic research as it moves to FP4
- Nvidia launches NIM Blueprints aims for more turnkey genAI use cases
MLPerf Inference 4.1 measured the Nvidia platform across multiple models including Llama 2 70B, Mistral 8x7B Mixture of Experts (MoE), Stable Diffusion and other models for recommendation, natural language processing, object detection, image classification and medical image segmentation.
"We did our first-ever Blackwell submission to MLPerf Inference. Not only was this the first Blackwell submission ever to MLPerf it was also our first FP4 submission," said Dave Salvator, Director of Accelerated Computing Products at Nvidia.

Key benchmark points:
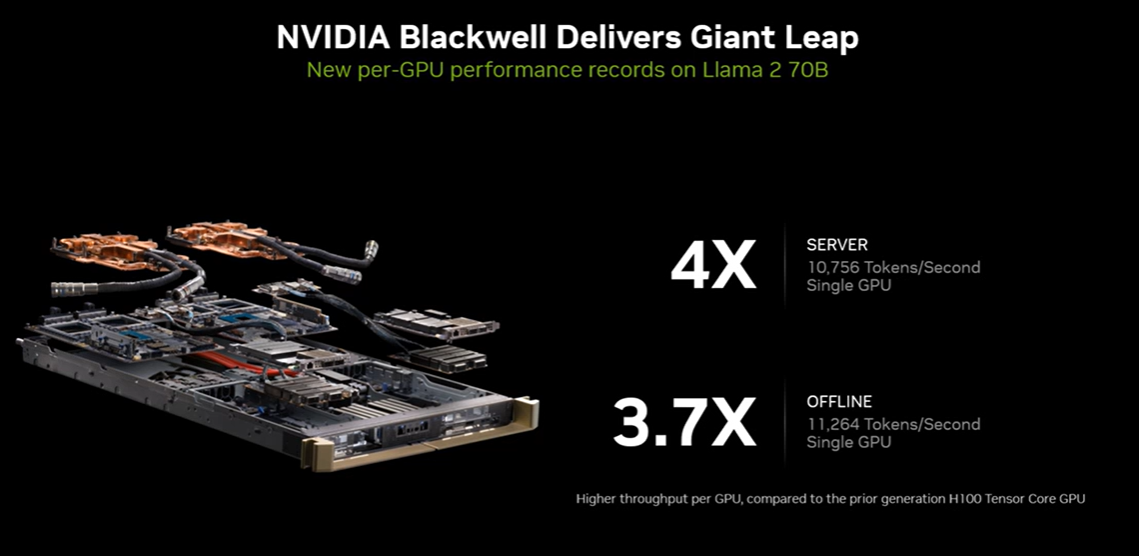
- Nvidia Blackwell hit new per GPU performance records on Llama 2 70B with 10,756 tokens/second single GPU, four times the performance of the previous generation. Offline performance was 3.7 times the performance.
- Nvidia Blackwell and FP4 on MLPerf Inference delivered high performance and accuracy on the Quasar Quantization System.
- HGX H200 and NVSwitch delivered 1.5x higher throughput compared to H100 on Llama 2 70B.

- Nvidia also emphasized that it is using software to improve performance by up to 27% on H100 systems in the field as well as H200. Nvidia said it has improved HGX H200 performance by up to 35% in one month on Llama 3.1 405B via software improvements.
- Jetson AGX Orin, Nvidia's edge platform for transformer models, saw a 6x boost in performance due to software optimization.

"The amount of software enabling and ecosystem enabling it takes to deliver great AI performance is really significant," said Salvator. "Yes, we make amazing hardware and architectures, but the software enabling is what really makes the big difference in terms of being able to realize the potential of the hardware. In any given generation of our GPUs and total platform we typically get between 2.5x more performance with ongoing software tuning."
- Nvidia outlines roadmap including Rubin GPU platform, new Arm-based CPU Vera
- Nvidia's 10Q filing sets off customer guessing game
- Nvidia acquires Run.ai for GPU workload orchestration
- Nvidia Huang lays out big picture: Blackwell GPU platform, NVLink Switch Chip, software, genAI, simulation, ecosystem
- Nvidia today all about bigger GPUs; tomorrow it's software, NIM, AI Enterprise

