
Nvidia has developed a system that preserved large language model (LLM) accuracy with less precision. The system, which will be outlined at the Hot Chips conference, highlights how Nvidia's AI game is becoming more about software and optimization as much as it is hardware.
In a briefing, Dave Salvator, Director of Accelerated Computing Products at Nvidia, outlined the Nvidia Quasar Quantization System and Research.
He outlined how Nvidia new Blackwell GPUs move to FP4--four bits of floating-point precision per operation. In a nutshell the shorter the floating-point string, the faster the execution. Moving to FP4 and reduced precision means faster compute, lower power and reduced data movement. The trick is preserving accuracy.
Salvator said Nvidia has been doing a lot of algorithmic work to preserve accuracy as it goes to FP4. "It's one thing to claim you have FP4 support in your chip. It is another thing entirely to actually make it work in real AI applications," said Salvator. "The amount of algorithmic work we have been doing to ensure that we preserve accuracy as we as we go to that reduced precision has been a substantial amount of work, and it's ongoing work."
- The generative AI buildout, overcapacity and what history tells us
- AI infrastructure is the new innovation hotbed with smartphone-like release cadence
-
DigitalOcean highlights the rise of boutique AI cloud providers | Equinix, Digital Realty: AI workloads to pick up cloud baton amid data center boom
Here's a look at the system and the output of an FP4 bunny. Click to enlarge the first slide.
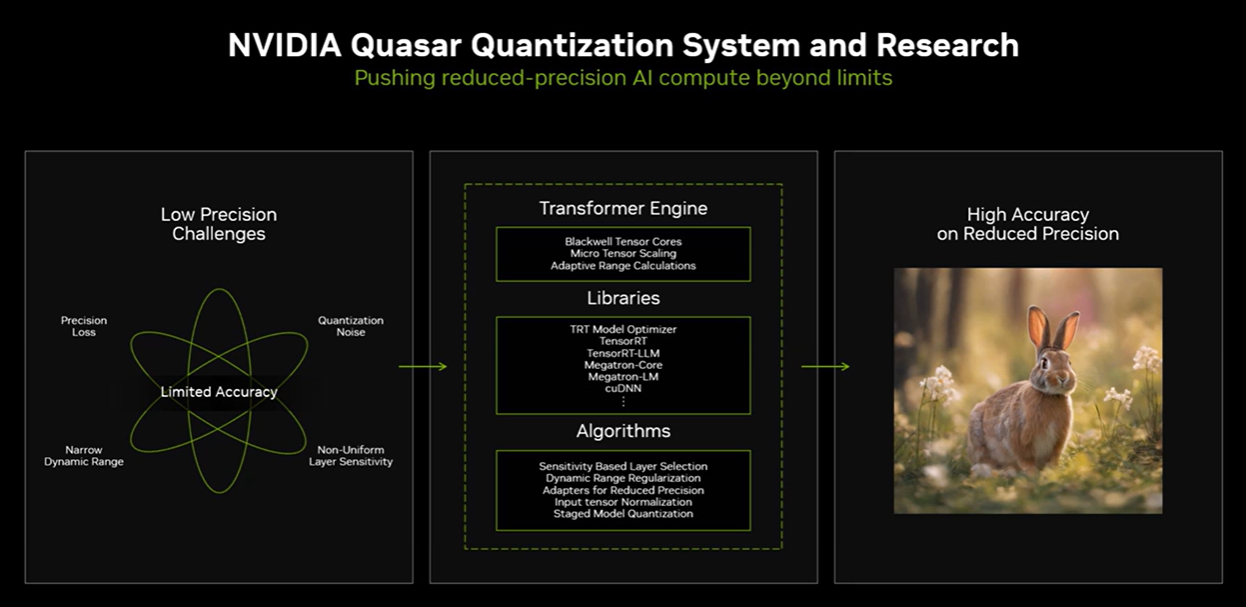

Salvator explained the importance of the FP4 generated bunny picture.
"What you see on the left-hand side is an AI generated image from Stable Diffusion where we use first FP16, and then we ask with the same prompt to generate that same image using FP4. Now you may notice there are some slight differences in the image, not so much around image quality, but for instance, how the bunny is posed. That's actually an artifact of doing AI generated imagery. If you run the same prompt through most text to image generators, what you'll see is that from run to run, the image generated will be slightly different. In other words, the image that gets generated is not entirely deterministic. It's not going to be the exact same image every time. What's more important to focus on is the image quality? And what you can see is that we've preserved a huge amount of the quality. In fact, nearly all of it when you look at that image that was generated using FP4."
Salvator noted that Nvidia's algorithmic research will land in developer libraries for software developers. The upshot from Nvidia's talk at the Hot Chips conference is that the company's Blackwell efforts revolve around a complete platform including switches, racks and cooling to go along with GPUs.
- Nvidia outlines roadmap including Rubin GPU platform, new Arm-based CPU Vera
- Nvidia's 10Q filing sets off customer guessing game
- Nvidia acquires Run.ai for GPU workload orchestration
- Nvidia Huang lays out big picture: Blackwell GPU platform, NVLink Switch Chip, software, genAI, simulation, ecosystem
- Nvidia today all about bigger GPUs; tomorrow it's software, NIM, AI Enterprise

Other talks from Nvidia at the Hot Chips conference include:
- A tutorial on liquid cooling systems with Blackwell including warm water direct-to-chip approaches.
- A talk on how Nvidia uses generative AI to build its processors.
- And a deep dive into Blackwell architecture including shots of Blackwell-based systems and core components in the lab.
Nvidia is an AI player at Hot Chips, but rivals are also at the conference. Qualcomm, IBM, Intel and AMD are also giving talks.

