
Google Cloud updated Vertex AI with new models, context caching, provision throughput and a bevy of grounding updates with Google Search, third party data and an experimental "grounding with high-fidelity mode."
The Vertex AI enhancements were detailed by Google Cloud CEO Thomas Kurian in a briefing. Kurian's briefing highlights Google Cloud's cadence of Vertex AI updates from Google Cloud Next to Google I/O to those latest additions.
Kurian highlighted customers including Uber, Moody's and WPP leveraging Vertex AI and generative AI. Google Cloud has been touting the 2 million token context window for Gemini 1.5 Pro as well as the performance of Gemini 1.5 Flash. Gemini 1.5 models are generally available.
While touting its own models, Google Cloud, which is on a $40 billion annual revenue run rate, is also emphasizing choice as Kurian noted that Anthropic's Claude Sonnet 3.5 as well as new open-source models such as Mistral and Gemma 2 are available. Google Cloud also launched Imagen 3.
While models are nice, the Vertex AI updates outlined by Kurian really revolve around features that are aimed at enterprises that want to scale generative AI.

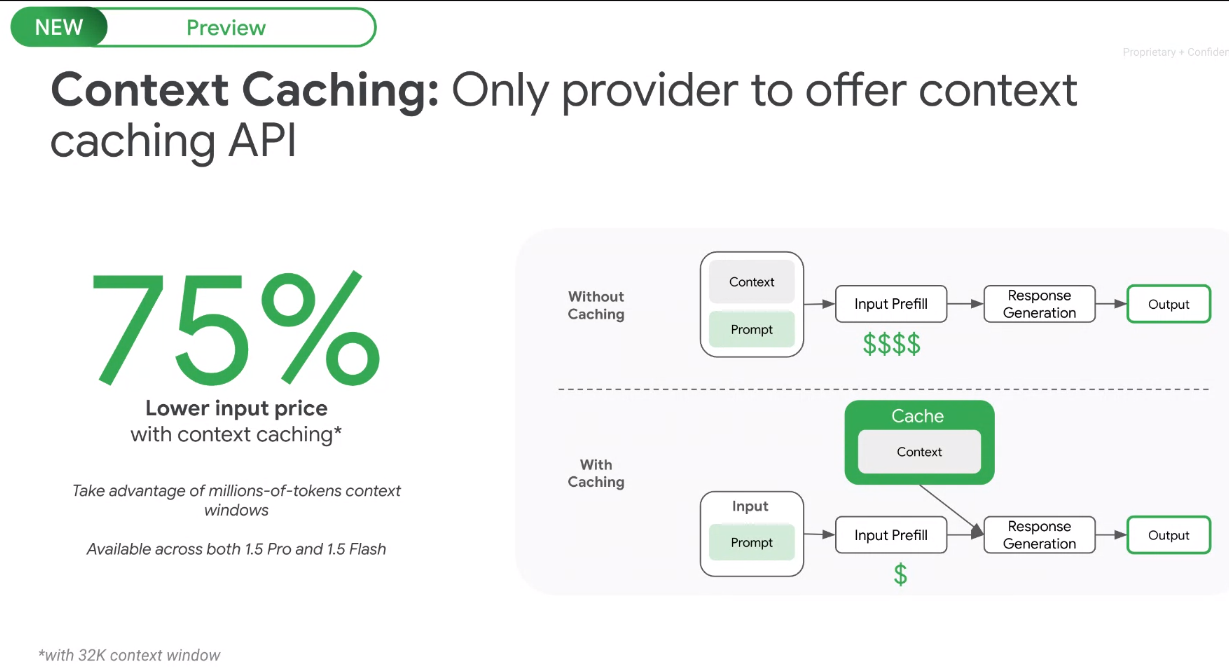
Kurian said Context Caching should lower costs for enterprises since you won't have to feed context into the model on each request. Kurian said:
"By introducing a context cache, you only need to give the model the input prompt. You don't have to feed in the context on each request. This is obviously super helpful in lowering the cost of input into the model. It becomes particularly helpful if you've got a long context window and you don't want to keep feeding that long context every time. It is also helpful in applications like chain of thought reasoning, where you want the model to maintain the context rather than must feed it and on every request. So that's a big step forward."
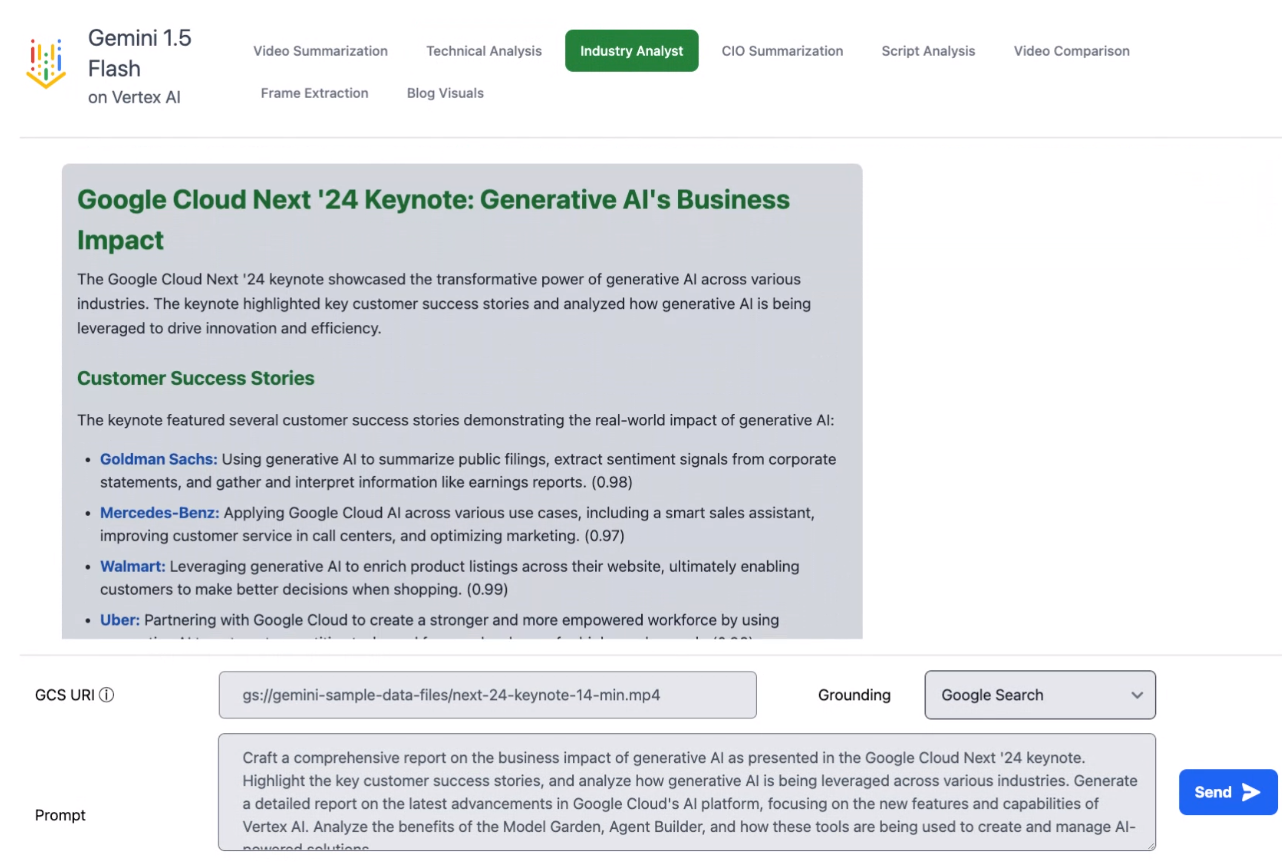
A live demo of Context Caching highlighted how you could analyze the Google Cloud Next keynote with Gemini 1.5 Flash and put together video clips and summaries designed for particular roles such as developers and CIOs.
A few key points about Context Caching:
- Data is in memory based on customer settings.
- Customers have two flavors with Context Caching--one based on how much you want to cache and another based on duration and time.
- With Context Caching, Google Cloud can more easily leverage its larger context windows in models.
- Context Caching can reuse content for multiple prompts and lead to a 75% savings in cost and performance.
- Behind the scenes Context Caching is maintained in Google Cloud VPC for data residency and isolation.
Provisioned Throughput is another addition to Vertex AI. Provision Throughput is designed to provide better predictability and reliability in production workloads. Customers can "essentially reserve inference capacity," said Kurian.
"Customers can still use pay as you go, but if they want to reserve a certain amount of capacity for running a large event or a big ramp of users platform customers can reserve capacity for a time," said Kurian, who said social media companies are using Provisioned Throughput. Snap is a big Google Cloud customer. Customers can use Provisioned Throughput to use new models when generally available or to get assurance on service levels and response times.
On the grounding front, Google is taking multiple approaches where it can leverage third party data and Google Search for timely prompts. The third-party grounding service will include data providers such as Moody's and Thomson Reuters.
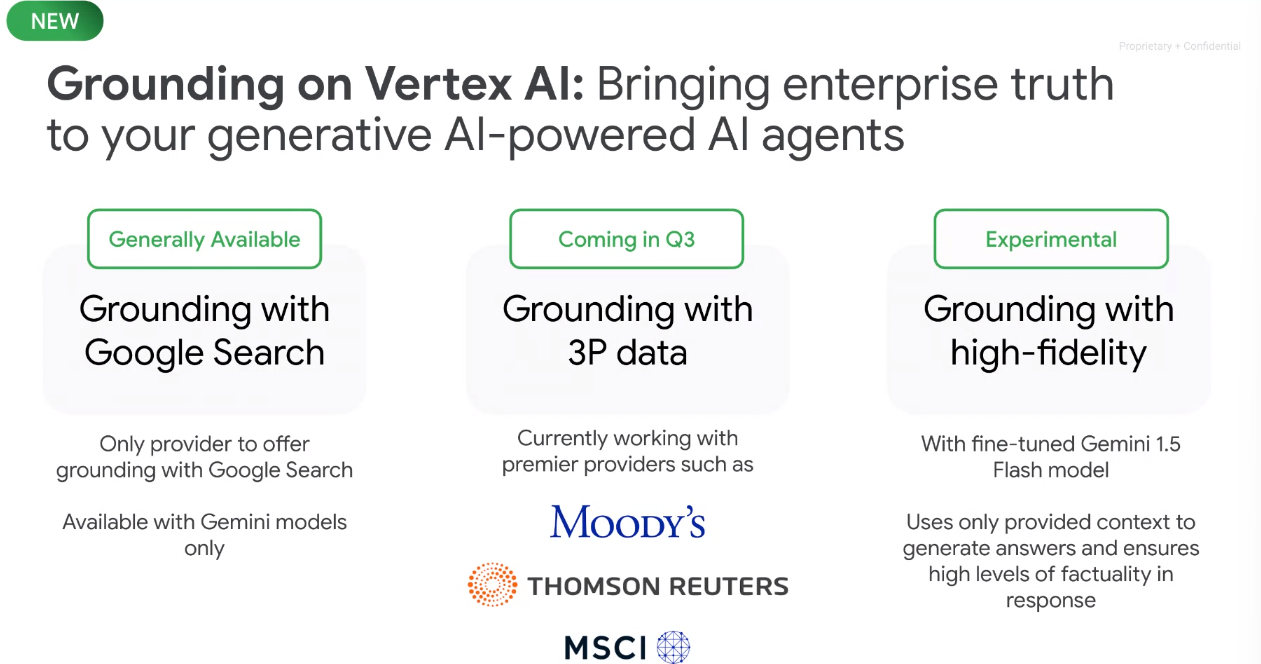
Grounding with high-fidelity mode is an experimental feature that includes a grounding score as well as a source. Kurian highlighted an example of a prompt asking about Alphabet's first quarter revenue and an answer with a grounding score. If the question was about Alphabet's third quarter 2024 earnings, the system looks at the context and notes that the quarter hasn't happened yet.
Kurian said:
"High-fidelity grounding is not just a feature of the grounding service. It's a feature of the model itself. The model has been adapted to provide more factuality in its response. In order to do that, the longer context window helps, because you can tell the model to pay attention to what I'm giving you on the input context, and don't get distracted by other things."
- Foundation model debate: Choices, small vs. large, commoditization
- Google Cloud Next: The role of genAI agents, enterprise use cases
- Google Cloud Next 2024: Google Cloud aims to be data, AI platform of choice
- Google Unveils Ambitious AI-Driven Security Strategy at Google Cloud Next'24
- Equifax bets on Google Cloud Vertex AI to speed up model, scores, data ingestion

Customer use cases
Nick Reed, Chief Product Officer at Moody's, said Google Cloud's grounding features are enabling his company to scale generative AI into production. "Grounding gives us an ability to be able to pair the power of LLMs with knowledge and as proprietary owners of knowledge facts and data," said Reed. "The ability to be able to combine those two things together empowers our customers to be able to use the outputs of the generative AI calls that we're building in actual decision-making processes. We're moving out of the experimental phase into a much more production and decision phase."
14 takeaways from genAI initiatives midway through 2024
Reed said the plan for Moody's is to use Google Cloud's grounding services as a distribution mechanism for its content because end users will be able to trust answers. Reed said:
"It feels like 2023 was the kind of year of experimentation and people were getting used to how this stuff works. Now we're starting to move into a world where we're saying I want to actually use this to drive efficiency in my organization and to be able to use it more directly in decision making and customer touching processes."
Stephan Pretorius, CTO of advertising firm WPP, said Gemini models are being used by the company for speed to market in marketing, which has become a critical KPI for enterprises.
"We use Gemini 1.5 Flash particularly for a lot of the operational automation tasks that we have in our in our business. Everything from brief refinement to strategy development and some ideation concepting tasks," said Pretorius, who said WPP is looking to automate marketing services and its content supply chain.
The WPP CTO added that Context Caching will be critical for the company since "it's not cheap to put 2 million tokens into a query." "If you only have to do that once and you can then cache it, then the entire pipeline of things that you do beyond that becomes a lot more cost effective," said Pretorius.
My take
With its Vertex AI updates, Google Cloud is addressing practical real-life use cases that are evolving from pilot to production. The Gemini 1.5 models have large context windows for bragging rights, but the main effort is to address individual use cases and scenarios.
The big win here is the Context Caching that can drive costs down for enterprises with a close second being the grounding with high-fidelity mode. The first addresses pain points today, but the second may become critical over time since it leverages Google Cloud's key advantage--access to real-time search data.
Kurian said the company is focusing on reducing latency with a family of models and fleshing out techniques like Context Caching that bring costs down. Add it up and what Google Cloud is ultimately building is an abstraction layer that manages context, grounding and other processes all the way down to the GPU and TPU.
More on genAI dynamics:
- OpenAI and Microsoft: Symbiotic or future frenemies?
- AI infrastructure is the new innovation hotbed with smartphone-like release cadence
- Don't forget the non-technical, human costs to generative AI projects
- GenAI boom eludes enterprise software...for now
- The real reason Windows AI PCs will be interesting
- Copilot, genAI agent implementations are about to get complicated
- Generative AI spending will move beyond the IT budget
- Enterprises Must Now Cultivate a Capable and Diverse AI Model Garden
- Financial services firms see genAI use cases leading to efficiency boom

