
Cloudflare said it is offering a "pay per crawl" plan where web sites will automatically block AI crawlers and can charge for access. Is this the start of the data dark ages for AI?
The move by Cloudflare makes a lot of sense. Publishers and content creators are providing data to AI models to consume for free as traffic tanks. Some sites have licensing deals, but many don't. As Cloudflare noted, people are getting content from models and not driving traffic to sites. We're consuming derivatives not original with large language models in the middle.
Cloudflare is proposing a system where news sites, publishers and social media platforms can be paid per crawl. Basically, we're talking about a pay wall for humans and machines.
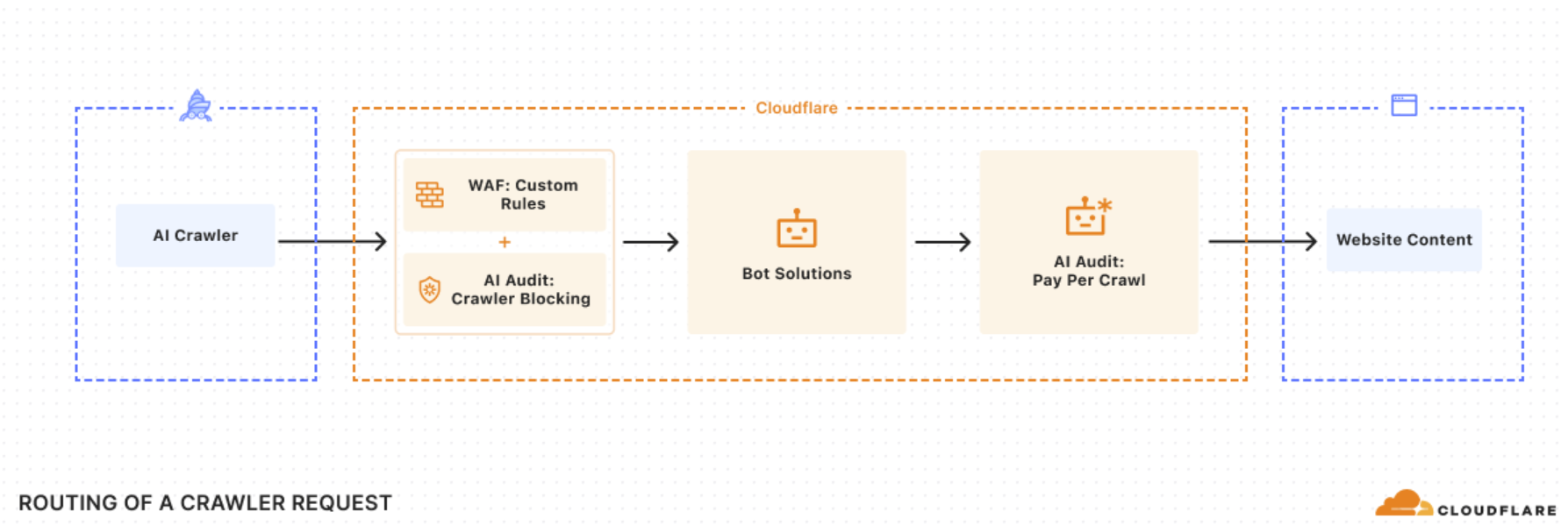
The pay per crawl system is in private beta and could be the start of similar models. While this effort is focused on content producers, it does raise a few interesting potential developments for enterprises.
Brands will want their content out there and would enable AI crawlers. The downside for users is that if all content creators blocked AI crawlers we'd have a web of marketing speak.
Will models advance without unfettered free access to content? If we live in the land of pay walls for humans and machines the data scarcity issue will only get worse. Constellation Research CEO R “Ray” Wang has noted that data is going to become scarce and create a data dark age in 2027.
- The data wars are just starting and agentic AI may be a trigger
- AI? Whatever. It's all about the first party data
- Generative AI's looming crap in, crap out data problem
- Meet Data Inc. and what a post AI company looks like

Constellation Research analyst Michael Ni said the Cloudflare move highlights three issues:
- It reflects the broader trend of open data, going dark as collective look to monetize
- It also reflects the shifting business model needed to fund quality information.
- Implications to those needing data to ensure accurate decisions - whether automated or guided.
Perhaps LLMs will be evaluated on their access to the most current and accurate information for grounding purposes. If grounding becomes a larger part of LLM evaluation, it's likely that Google and its Gemini models would have an edge.
How Cloudflare's pay per crawl system develops is worth watching and enterprises will need to ponder the following going forward.
- What's the impact on model performance if there's data scarcity for new information?
- Should industries form data collectives to ensure there is accurate information for model training?
- Will enterprises need to rely on synthetic data setups if a data dark age emerges?
- How do content pay roads impact AI agents? Cloudflare said:
"The true potential of pay per crawl may emerge in an agentic world. What if an agentic paywall could operate entirely programmatically? Imagine asking your favorite deep research program to help you synthesize the latest cancer research or a legal brief, or just help you find the best restaurant in Soho — and then giving that agent a budget to spend to acquire the best and most relevant content."

