
IBM promises ‘AI Anywhere,’ but will customers trade one form of lock-in for another?
IBM Think, the company’s big annual event, visited San Francisco for the first time February 12-15, bringing some 30,000 customers, partners, press and analysts to the Moscone Center. What’s next for IBM and will it reignite growth?
Most of what I heard at Think 2019 seemed geared to existing IBM customers who are all-in on its stack. That’s good news for many long-time IBM customers, but I have to wonder whether more heterogeneous firms or entirely new customers will be attracted to what seemed like an all-IBM offering designed for multi-cloud deployment? Here’s my take on the big “AI Anywhere” announcement.
IBM Promises ‘AI Anywhere’
IBM’s Watson Anywhere promise, which was announced by CEO Ginni Rometty during her keynote and detailed in separate analyst and customer presentations, sounded compelling in principle. The idea is to facilitate a hybrid, multi-cloud world, and most organizations Constellation Research talks to accept that the combination of on-premises and cloud-based deployments will be a reality for some time to come. IBM’s envisioned “anywhere” deployment choices include on-premises and the IBM Cloud, of course, but also Amazon Web Services (AWS), Microsoft Azure (Azure), Google Cloud Platform (GCP) and RedHat Openshift and OpenStack (see IBM Watson Anywhere slide, below).
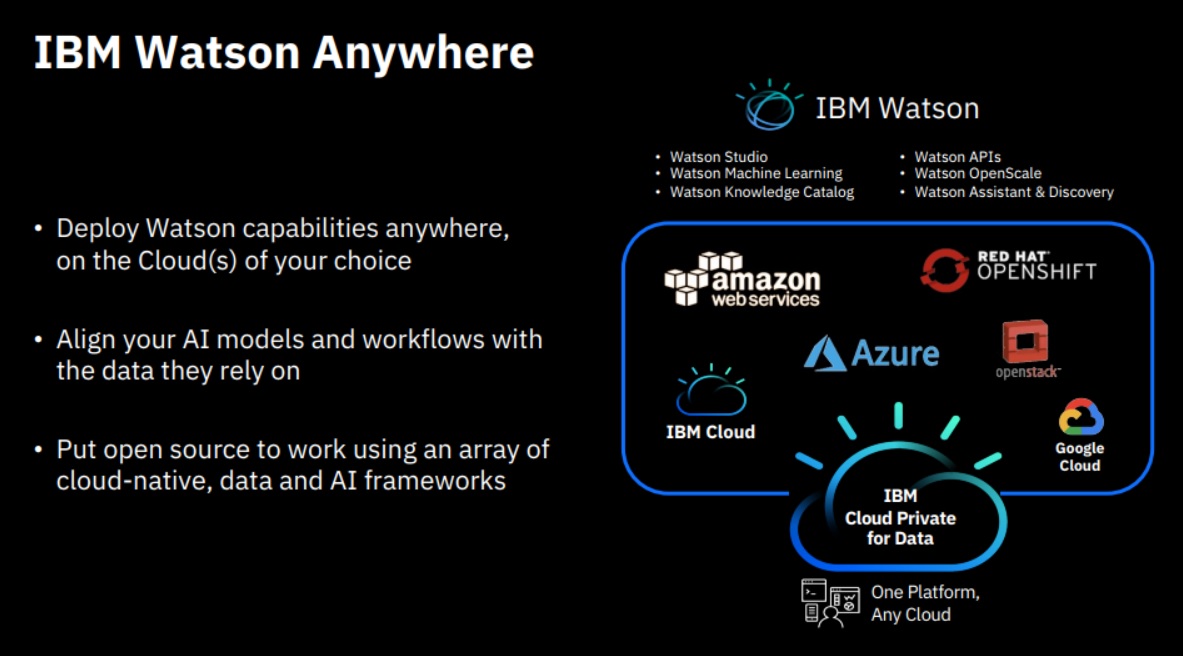
Source: IBM
The “Watson Anywhere” offerings described at Think showed IBM’s complete stack, including the AI options and the underlying information architecture (IA). IBM will use the Kubernetes and containerization capabilities of (the confusingly named) IBM Cloud Private (ICP) to deploy all or parts of the portfolio on the on-premises, private cloud and public-cloud options listed above. IBM’s multi-cloud offering on AWS will be the first of IBM's third-party cloud deployment options to be introduced this year. IBM executives often use the line “there’s no AI without IA,” and the slide below seems to suggest that IBM's AI is inextricably tied to its IA, meaning IBM Cloud Private for Data (ICP/D), but that's not the case. You can take more of an a la carte approach, as I discuss below, but execs did a better job of detailing the IBM stack than they did of explaining the modularity and flexibility of the portfolio to work with the components and services that customers might use on other public clouds.

Source: IBM
As for the IBM stack, ICP/D bundles together microservices-enabled capabilities to collect, organize, and analyze data, as shown in the slide below. The “collect” services embedded in ICP/D include the Db2 family (Db2 itself, Db2 Warehouse, Db2 Event Store) and Hadoop, Spark and IBM BigSQL. The “organize” services include capabilities from the InfoSphere brand, including DataStage integration, cleansing, data masking and governance capabilities. The “analyze” aspects of ICP/D include foundations from SPSS, Cognos and Watson Studio. There are also open source technologies in the mix -- like Hadoop, Spark, Elastisearch, Flink and more -- but as you can see below, there are a lot of IBM technologies under the hood in ICP/D.
IBM Cloud Private For Data
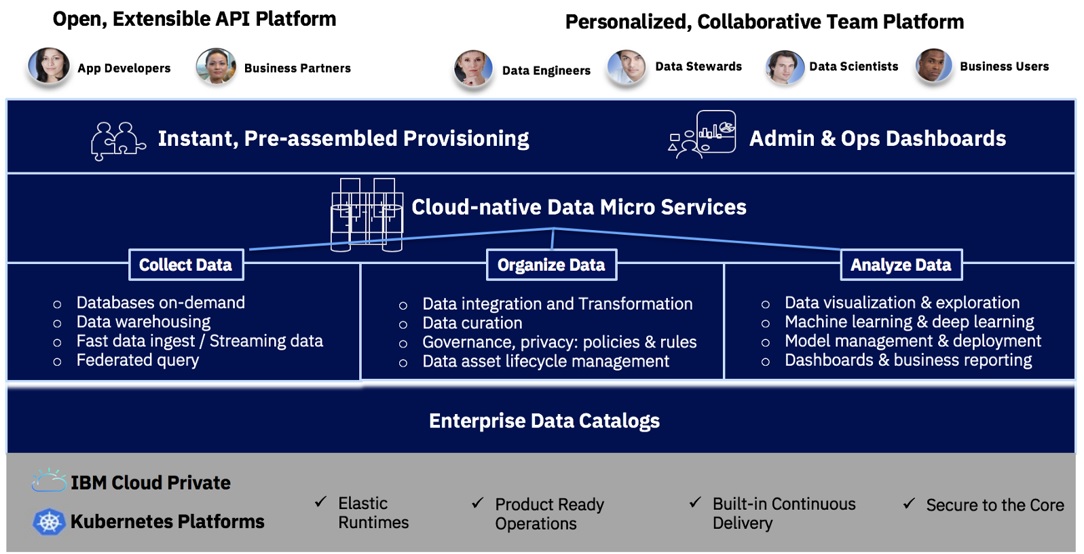
Source: IBM
MyPOV on IBM’s Multi-cloud Offering
IBM executives argued that Watson Anywhere will help companies break down the “walled gardens,” meaning various forms of vendor lock-in, on the major public clouds. But I doubt many customes will want to go to the opposite extreme of locking into all IBM technologies wherever they choose to deploy workloads. I see those interested in multi-cloud as more likely to be interested in mixing and matching capabilities, including some native to those third-party clouds, because they 1. Have significant amounts of data on those clouds, 2. Run significant numbers of applications on those clouds and/or 3. Want to use best-of-breed capabilities available on those clouds.
In my recent case study report on Royal Dutch Shell, Daniel Jeavons, the company’s general manager of data science, explained that the energy giant is using both AWS and Azure, tapping what it thinks of as interchangeable, but low-cost and quickly scalable information architecture available on each cloud. For example, Shell uses Redshift Spectrum, S3, Databricks, MySQL, Spark and Hadoop services on AWS and what Jeavons described as more-or-less equivalent services on Azure, including Azure SQL Data Warehouse, Azure Blob Storage, Databricks and MySQL, Spark and HDInsight.
Shell sees what it describes as its “data science platform” as the part that it wants to be portable across hybrid and multi-cloud deployments. That platform is a mix of non-cloud-specific software including Alteryx, MATLAB, Python, R, and R Studio. So in Shell’s case, the IA is seen as interchangeable while the AI and data-science capabilities – and the models developed thereon – are the prized part that the company wants available in hybrid- and multi-cloud fashion, applicable wherever data lives.
IBM execs did acknowlede, when asked, that there’s nothing preventing customers from deploying individual components of its modular AI stack. To me, some of the more attractive components of the overall stack are Watson Studio, which includes a nice collection of open source frameworks, and Watson OpenScale, which addresses the monitoring and optimization aspects of the model-development-and-deployment lifecycle often neglected in data science offerings. OpenScale also addresses model interpretability and bias detection, which are emerging as important challenges. If you just want to use Watson Studio and OpenScale, you could use ICP (without the “for Data,” IA part) to deploy just those components on the range of IBM’s hybrid and multi-cloud deployment options. As show below, for example, Watson Studio and OpenScale clould run on AWS or Azure with those clouds being the runtime environment.
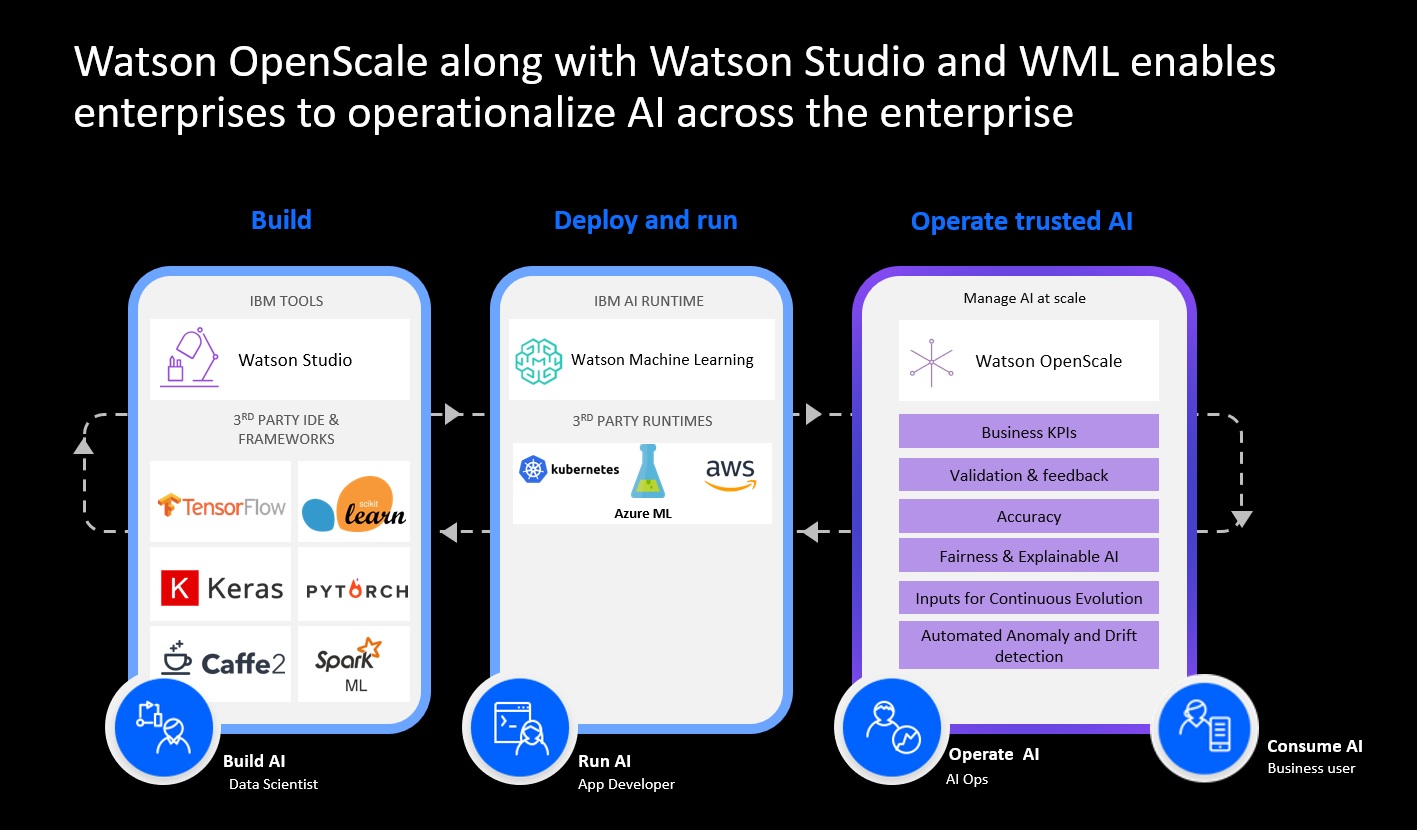
Source: IBM
The advantage of a more a la carte approach would be, for example, bringing a consistent data science and model-management environment to a range of deployments, drawing on data where it lives (assuming it’s already on that cloud) rather than moving it or replicating it onto a separate platform (ICP/D running on IaaS). But instead of talking up flexibility and choice, IBM spoke to IBM customers about running the IBM stack on rival clouds using a bare minimum of capabilities from those clouds.
I suppose it’s a breakthrough that IBM is even acknowledging the customer desire to run workloads on rival clouds – something Microsoft and Oracle don’t discuss. But if you’re going to talk up multi-cloud support, in my book you might as well talk up the ability to work with data where it lives and bring what the customer loves most (and not everything) to a third-party cloud. I wouldn't expect IBM execs to talk up the components and services customers might want to use on other clouds, but it would have helped the deploy-anywhere story to hear more about the modularity of the portfolio and the availability of REST APIs and more to play nicely on third-party clouds.