

![]()
Google researchers have come up with a method for machine learning that tackles two of the technology's biggest pain points to date: End-user privacy and device and network resource consumption.
It's called Federated Learning, and while still in the labs, could have a profound influence going forward. Here are the details from Google's official blog post:
Federated Learning enables mobile phones to collaboratively learn a shared prediction model while keeping all the training data on device, decoupling the ability to do machine learning from the need to store the data in the cloud.
It works like this: your device downloads the current model, improves it by learning from data on your phone, and then summarizes the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on your device, and no individual updates are stored in the cloud.
Careful scheduling ensures training happens only when the device is idle, plugged in, and on a free wireless connection, so there is no impact on the phone's performance.
Google is testing Federated Learning in Gboard, the Android keyboard. Gboard offers up suggested queries to users, and Federated Learning captures whether the user accepted the suggestion. It stores and processes this information locally.
Google notes that Federated Learning, while innovative, presented new logistical challenges to overcome:
[I]n the Federated Learning setting, the data is distributed across millions of devices in a highly uneven fashion. In addition, these devices have significantly higher-latency, lower-throughput connections and are only intermittently available for training.
These bandwidth and latency limitations motivate our Federated Averaging algorithm, which can train deep networks using 10-100x less communication . The key idea is to use the powerful processors in modern mobile devices to compute higher quality updates than simple gradient steps. which excel on problems like click-through-rate prediction.
Google has thought through the potential benefits Federated Learning has for end-users quite thoroughly. It uses an aggregation protocol that requires 100s or thousands of users to have participated in an update before a server can decrypt the information, meaning no person's data can be exposed on its own.
There's much more detail in Google's full blog post, which is well worth a read. Here's a graphic illustrating Federated Learning's architecture (credit: Google).
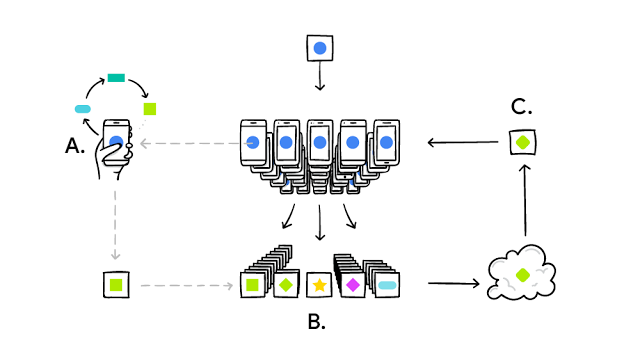
One of the biggest challenges in machine learning is the task of collecting enough data to drive accurate predictions and decisions, and Federated Learning is aimed squarely at that target, says Constellation Research VP and principal analyst Doug Henschen.
Data federation, of course, is nothing new as a concept, but by applying a federated approach to machine learning training, Google is cleverly side-stepping the challenge of having to move data to one, centralized location for training, he adds. "The data-movement alone is a big challenge, and once centralized, data storage and analysis is a big expense."
"This federated approach to training machine learning models seems to promise multiple advantages: eliminating data-movement requirements, taking advantage of remote computing capacity, and side-stepping privacy and security concerns all while delivering more accurate predictions thanks to the use of more data in the training process," Henschen says.
That said, there are tradeoffs, such as how long it might take to train a model, "but Federated Learning is a novel and promising approach to a big stumbling block to predictive success."
24/7 Access to Constellation Insights
Subscribe today for unrestricted access to expert analyst views on breaking news.

